- 나쁜 코드를 쓰는 시간을 줄이면 어때요?
- 네, 그리고 줄 바꿈은 고양이 모양으로 하자요!

현재 문서에는 RAG 및 의미 분석 기능 지원이 없습니다.
IDE
코드를 바탕으로 그 코드가 무엇을 하는지 설명하는 기능은 어떨까요?
PyCharm/IDEA에서 작업 중이라면 Devoxx 플러그인을 사용할 수 있으며, 이 플러그인은 LLM을 호출하여 코드 리뷰 및 원하는 모든 작업을 수행할 수 있습니다.
아래에서는 이 플러그인을 LM Server API 서비스와 연동하는 방법을 살펴보겠습니다.
기능
- 로컬 및 클라우드 언어 모델 지원: Anthropic, Groq, Ollama, OpenAI, …
- 선택된 코드 조각에 대한 팁 제공
- 코드 리뷰
- 코드가 무엇을 하는지 설명 생성
설치 계획
- 플러그인 설치 (아래 참조)
- Ollama, LMStudio 또는 GPT4All이 실행 중인지 확인
- 설정에서 프롬프트를 업데이트
- 선택 사항: 클라우드 LLM 제공업체의 API 키 추가
- 플러그인 사용 시작
플러그인을 마켓플레이스에서 설치하세요. 만약 설치가 안 되는 경우 (수출 통제 규정으로 인해, 오픈소스는 가능함):
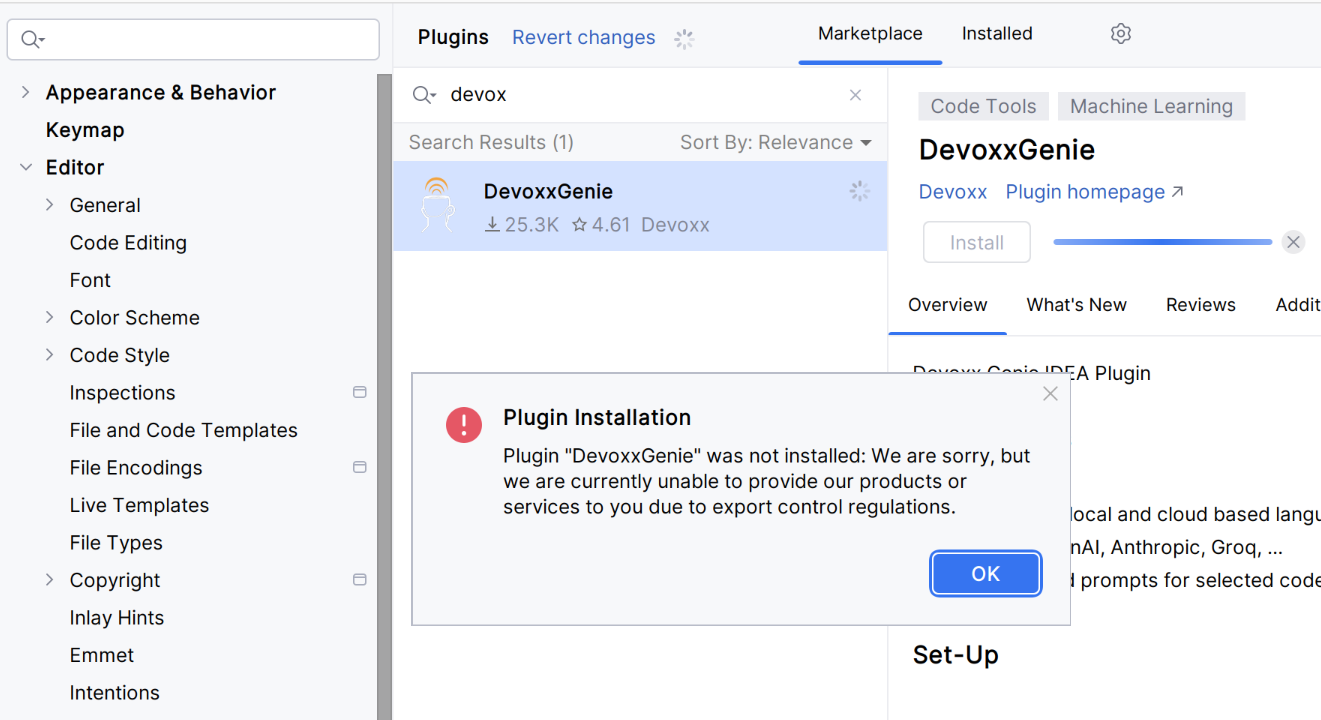
…이 경우 다른 컴퓨터에서 이 플러그인을 복사하거나 GitHub에서 다운로드하세요. 다음 폴더와 파일을 주의해서 확인하세요 (Ubuntu 예시):
# 홈 디렉토리 내에서
$ find . -iname 'devoxx*'
./.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml
./.cache/JetBrains/PyCharmCE2025.1/DevoxxGenie
./.cache/JetBrains/PyCharmCE2025.1/plugins/DevoxxGenie.zip
./.local/share/JetBrains/PyCharmCE2025.1/DevoxxGenie
```- DevoxxGenie.zip 파일을 `~/.local/share/JetBrains/PyCharmCE2025.1` 폴더 또는 IDEA에 따라 해당 폴더에 압축해 풀어주세요. 제 경우 PyCharmCExxx 폴더는 없었기 때문에 수동으로 생성해야 했습니다.
- `~/.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml` 설정 파일을 업로드해주세요.
- 선택 사항입니다. 플러그인과 그 아카이브를 캐시에 추가해야 할 수도 있습니다.
이제 IDE를 실행하면 설치된 플러그인 목록에 미리 설정된 설정이 적용된 플러그인이 보일 것입니다:

## 설정
1. 플러그인 설치 후, 메뉴의 **File** → **Settings**로 이동하여 LLM의 설정을 조정하세요. 예를 들어, 온도, 최대 출력 토큰 수, 재시도 횟수, 타임아웃 등을 설정할 수 있습니다. 원하시면 LLM API 키를 추가로 입력할 수도 있습니다.
> DevOps는 API 서비스를 제공할 수 있으며, 이는 보안이 없는 HTTP 서버로 동작합니다. 민감한 데이터를 다루는 경우, 이 서비스를 원격으로 사용하지 마세요. 왜냐하면 트래픽이 탈취될 수 있고, 공개된 데이터가 해커에 의해 악용될 수 있기 때문입니다.
LM Studio에서 컨텍스트 윈도우를 올바르게 설정하려면 URL `http://localhost:1234/api/v0`을 사용해야 한다고 명시되어 있지만, 이는 오류입니다. 모델을 로드할 때 컨텍스트 윈도우를 수동으로 확장해야 합니다 (예: 4096 → 8192).

**Prompts** 탭에서는 시스템 프롬프트와 사용자 요청을 구성할 수 있습니다.
시스템 프롬프트는 사용자 요청과 함께 전송되며, 작업 범위, 검색 제약 조건, 출력 형식 등을 정의합니다. 이는 매우 중요한 요소입니다.
시스템 프롬프트에서 다음 줄을 제거하세요:
The Devoxx Genie is open source and available at GitHub - devoxx/DevoxxGenieIDEAPlugin: DevoxxGenie is a plugin for IntelliJ IDEA that uses local LLM's (Ollama, LMStudio, GPT4All, Jan and Llama.cpp) and Cloud based LLMs to help review, test, explain your project code..
You can follow us on Bluesky @ @devoxxgenie.bsky.social on Bluesky.
모든 언어 모델은 마크다운 표기법을 이해하므로, 목록, 서브포인트, 코드 블록 등 구조화된 프롬프트를 작성할 수 있습니다.
> DevOps: 기본 프롬프트(제약 조건 포함)는 다음 파일에 정의되어 있습니다.
>
> ```
> ~/.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml
> ```
>
> 모델은 러시아어 요청을 영어로 번역할 수 있습니다. 잘못된 용어 번역은 응답 품질에 큰 영향을 미치며, 질문이 부정확할 경우도 마찬가지입니다. 예를 들어, "페이지에 설명이 있는 곳을 찾아줘"와 "페이지 링크를 제공해줘"라는 두 질문을 비교해보세요. 어느 경우에 봇이 링크를 제공할까요? 정확히 원하는 것을 요청하세요 (사람에게 문제를 제시할 때와 같은 방식으로).
<br>
2. **Web search** 탭에서는 모델이 인터넷과 상호작용할 수 있는 옵션(기본값으로 활성화됨)이 있습니다. Google Web Search 개인 API 키가 있다면 사용할 수 있습니다.
3. RAG 설정의 세부 사항은 이후에 추가될 예정입니다:

## 플러그인 사용 방법
1. 이제 원본 파일을 열고 코드 조각을 선택하거나, 프로젝트 파일을 우클릭하여 컨텍스트 창에 추가하세요.
**Devoxx** 버튼을 클릭하세요:
터미널 창에 쉘 코드가 표시되고, 프로젝트 파일이 있는 폴더들이 열려 있습니다. (AI 이미지 캡션)|600x305](upload://2aBOJ4FADHQqiRrCP6OETygGNFT.png)
2. 적절한 모델을 드롭다운 목록에서 선택하세요. 아쉽게도 목록에 일부 모델은 사용에 적합하지 않을 수 있습니다(예: 임베딩 모델). 모델 필터는 설정할 수 없습니다.

3. 초대 문맥을 정의한 후 질문을 제출하거나 다음 명령어를 사용할 수 있습니다: `/test`, `/review`, `/explain`, `/help`.
4. 선택한 LLM으로부터 응답을 받으면 코드 위의 버튼을 사용하여 예시 코드를 클립보드에 복사하거나 파일에 붙여넣을 수 있습니다. 또는 스크립트의 작동 설명을 Markdown 형식으로 작성된 텍스트를 받을 수 있으며(기본적으로 영어로 제공되나, 프롬프트에서 원하는 언어를 지정할 수 있습니다).
## 출력 예시
모델 `qwen2.5-coder-14b-instruct`를 사용한 `/explain` 명령어의 스크립트 분석 결과:
- 코드 줄 수: 500
- 모델 컨텍스트 윈도우: 8192 (기본값 4096에서 확장됨)
- 토큰 수:
```json
"usage": {
"prompt_tokens": 6298,
"completion_tokens": 620,
"total_tokens": 6918
}
-
RTX 5060Ti 카드에서의 분석 시간: 10초
-
응답 품질: 내 상황에서 매우 만족스럽습니다. 모델은 코드와 주석을 바탕으로 구조화된 설명을 생성하여 이 코드의 기능을 명확히 설명해 줄 수 있었습니다.
스포일러
물론입니다! 이 스크립트를 더 쉽게 이해할 수 있도록 주니어 개발자에게 설명해 드리겠습니다.
개요
이 스크립트는 Tesseract를 사용해 PDF 및 이미지 파일(JPG/JPEG)을 처리하는 데 사용됩니다. PDF가 텍스트를 포함하는지 확인하고, 필요 시 TIFF 및 PNG 형식으로 변환한 후 OCR을 수행합니다. 모든 작업은 자세한 보고서를 위해 로그로 기록됩니다.
핵심 구성 요소
-
색상 정의:
GREEN및NC는 터미널에서 색상 출력을 위한 변수입니다.
-
도움말 함수 (
show_help):- 스크립트 사용법, 설명, 옵션, 실행 예시를 제공합니다.
-
인자 파싱:
while루프와case문을 사용해 명령줄 인자를 파싱합니다.- DPI 설정, 압축 유형, OCR 언어, 처리 후 TIFF/PNG/TXT 파일 유지 여부 등의 옵션을 제공합니다.
-
유효성 검사:
- 제공된 DPI가 유효 범위(72~1200)에 있는지 확인합니다.
- 압축 알고리즘이 지원되는 유형(
group4,lzw,zip)인지 확인합니다.
-
로그 설정:
- 모든 작업과 출력을 기록할 로그 파일을 초기화합니다.
-
파일 탐색:
- 지정된 디렉터리 또는 제공되지 않은 경우 현재 디렉터리에서 PDF 및 JPG/JPEG 파일을
find명령어로 탐색합니다.
- 지정된 디렉터리 또는 제공되지 않은 경우 현재 디렉터리에서 PDF 및 JPG/JPEG 파일을
-
PDF 파일 처리:
- 각 PDF에 대해
pdftotext를 사용해 텍스트가 이미 존재하는지 확인합니다. - 텍스트가 존재하면 텍스트 포함 PDF로 로그 기록합니다.
- 텍스트가 없으면 TIFF 및 PNG 형식으로 변환 후 TIFF에 OCR을 수행합니다.
- 각 PDF에 대해
-
이미지 파일 처리:
- 각 JPG/JPEG 파일에 대해 Tesseract를 직접 사용해 OCR을 수행합니다.
-
통계 계산:
- 인식된 총 문자 수, 단일 파일에서 최대 문자 수, 문자 수 분포 등 다양한 통계를 계산합니다.
- 스캔된 PDF 비율 및 평균 인식 속도를 계산합니다.
-
요약 생성:
- 처리된 모든 파일, 통계, 사용된 옵션을 포함한 상세 요약 보고서를 생성합니다.
- 이 요약은 터미널과 로그 파일에 모두 기록됩니다.
사용 예시
특정 옵션을 사용해 스크립트를 실행하는 예시:
./work2.sh --dpi 600 --compress lzw --lang rus+eng --no-keep-tiff --no-keep-txt ./docs
```이 명령은 DPI를 600으로 설정하고, TIFF 파일에 LZW 압축을 사용하며, OCR에는 러시아어와 영어를 지정하고, 처리 후 TIFF/PNG/TXT 파일을 유지하지 않습니다.
### 결론
이 스크립트는 OCR 기능을 갖춘 PDF 및 이미지의 배치 처리를 위한 종합적인 도구입니다. 상세한 로깅 및 통계를 제공하여 문서 처리 작업에서 자동화 및 분석에 유용합니다.
결론
기능이나 문서화를 위한 최적의 해결책을 찾는 데 매우 유용한 도구입니다.
작동 방식
개발 중인 전체 흐름은 다음과 같습니다. 다음 글에서는 GitLab에서 머지 리퀘스트(MR) 전에 AI 코드 리뷰를 사용하는 방법에 대해 설명하겠습니다.
graph LR
classDef pclass fill:#f5f5dc
classDef wclass fill:#f96
classDef pmclass fill:#4f7
classDef yclass fill:#ff9
classDef oclass fill:#ffbf00
B(IDEA) -- |코드 사전 검토| B1(AI Devoxx):::pclass
B1 -- C(수정):::wclass
C -- D{자체 검토}:::oclass
B -- |너의 코드가 완벽하다| F
F -- H2{코드 리뷰}:::oclass
H2 -.- |수정 필요| B1
D -- |검토 완료| F(MR):::pmclass
H2 -- E(병합)