— А что, если сократить время написания плохого кода?
— Да, и давайте перенос строки будем делать в виде котика!
В инструкции пока нет поддержки RAG и семантики.
IDE
А как вам такая возможность: по коду составлять описание, что он делает?
Если вы работаете в PyCharm/IDEA, то вам может быть доступен плагин Devoxx, который умеет обращаться к LLM с целью кодревью и всем, что вы его попросите.
Ниже рассмотрен вариант связки плагина с API-сервисом от LM Server.
Возможности
- Поддержка локальных и облачных языковых моделей: Anthropic, Groq, Ollama, OpenAI, …
- Подсказки для выбранных фрагментов кода
- Ревью кода
- Составление описания, что делает код.
План установки
- Установите плагин (см. ниже)
- Убедитесь, что у вас запущены Ollama, LMStudio или GPT4All
- Обновите промпты в настройках
- Необязательно: Добавьте ключи API для облачных LLM-провайдеров
- Начните использовать плагин
Выполните установку плагина из маркетплейса. Если по какой-то причине плагин не устанавливается (из-за ограничений контроля экспортных поставок, опенсорс да):
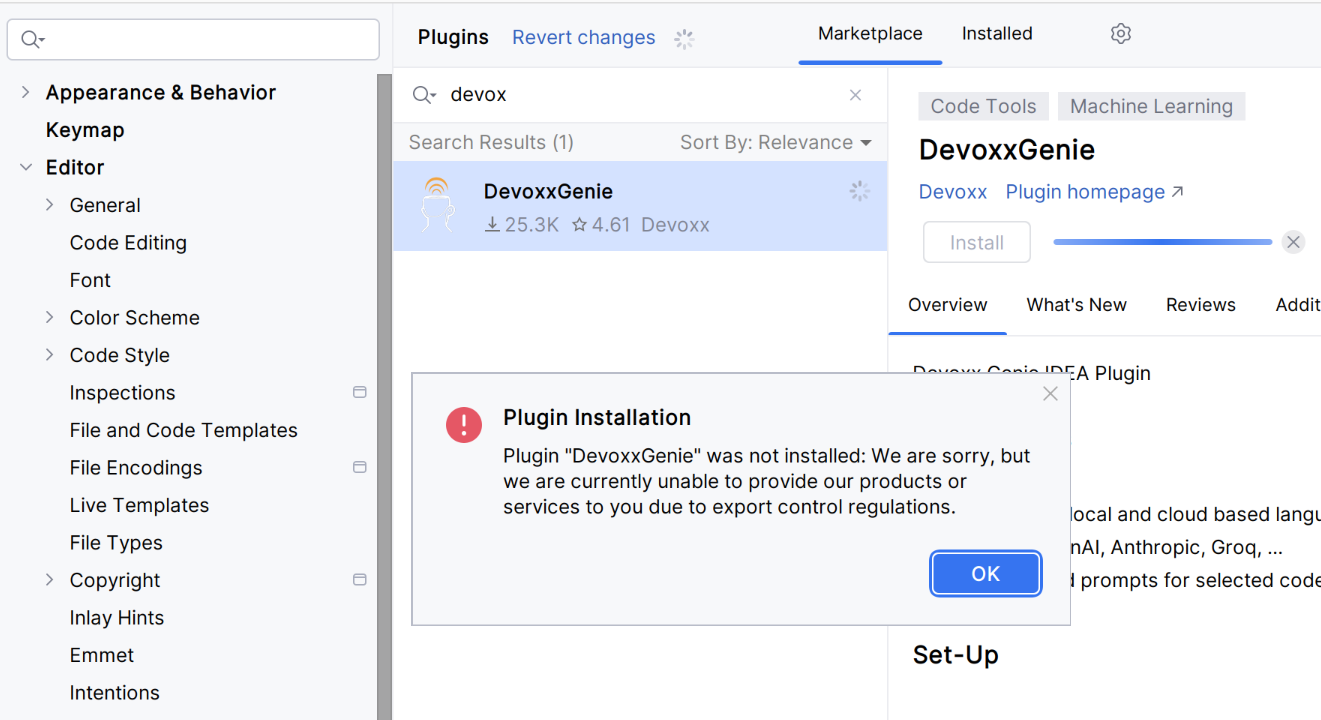
{kind=link}
…вы можете скопировать этот плагин с другого компьютера или GitHub. Обратите внимание на следующие папки и файлы (пример с Ubuntu):
# в домашней папке
$ find . -iname 'devoxx*'
./.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml
./.cache/JetBrains/PyCharmCE2025.1/DevoxxGenie
./.cache/JetBrains/PyCharmCE2025.1/plugins/DevoxxGenie.zip
./.local/share/JetBrains/PyCharmCE2025.1/DevoxxGenie
```- Распакуйте файл DevoxxGenie.zip в папке `~/.local/share/JetBrains/PyCharmCE2025.1` или в IDEA, в зависимости от ситуации. В моём случае папку PyCharmCExxx пришлось создавать вручную — её не было.
- Разместите конфигурационный файл `~/.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml`.
- Необязательно. Возможно, вам понадобится добавить плагин и его архив в кэш.
Теперь запустите IDE — вы должны увидеть плагин с предустановленными настройками (на вкладке Installed):

## Настройка
1. После установки плагина перейдите в настройки программы (через меню File), чтобы настроить параметры LLM, такие как температура, максимальное количество токенов вывода, повторные попытки и тайм-ауты. При желании вы также можете добавить облачные ключи API LLM, если хотите их использовать.
> DevOps для вас может подготовить сервис API, работающий как незащищённый HTTP-сервер. Не используйте его удалённо, если вы работаете с чувствительными данными, поскольку трафик может быть перехвачен, и открытые данные будут использованы злоумышленниками.
Сказано, что для правильного определения контекстного окна в LM Studio нужно использовать URL http://localhost:1234/api/v0 — это, вероятно, ошибка. Контекстное окно модели приходится увеличивать при её загрузке (4096 → 8192).

На вкладке Prompts вы можете сконфигурировать системный промпт и пользовательские запросы.
Системный промпт — это запрос, который отправляется вместе с пользовательским запросом и определяет область задачи, ограничения поиска и задаёт формат выдаваемой информации. Это критически важный момент.
Удалите из системного промпта строки:
The Devoxx Genie is open source and available at GitHub - devoxx/DevoxxGenieIDEAPlugin: DevoxxGenie is a plugin for IntelliJ IDEA that uses local LLM's (Ollama, LMStudio, GPT4All, Jan and Llama.cpp) and Cloud based LLMs to help review, test, explain your project code..
You can follow us on Bluesky @ @devoxxgenie.bsky.social on Bluesky.
Все языковые модели понимают разметку Markdown, поэтому вы можете составлять структурированные промпты со списками, подпунктами, блоками кода.
> DevOps: дефолтные промпты (запросы с ограничениями) заданы в файле
>
> ```
> ~/.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml
> ```
>
> Модели имеют возможность переводить русские запросы на английский. Неправильный перевод терминов может сильно повлиять на качество ответа, равно как и неточный вопрос. Сравните запросы: «найди страницу с инструкцией» и «предоставь ссылку на страницу». Как думаете, в каком случае бот предоставит ссылку? Запрашивайте строго то, что ожидаете (прямо как в постановке задачи человеку).
<br>
2. На вкладке Web search находится опция взаимодействия модели с интернетом (включена по умолчанию). Если у вас есть персональный ключ Google Web Search, вы можете использовать его.
3. Детали настройки RAG будут добавлены позже:

## Работа с плагином
1. Теперь либо откройте исходный файл и выберите фрагмент кода, либо щёлкните правой кнопкой мыши на файле проекта, чтобы добавить его в контекст окна.
Нажмите кнопку <kbd>Devoxx</kbd>:Отображается окно терминала с кодом shell, а также открытые папки с файлами проекта. (Подпись к изображению от AI)|600x305](upload://2aBOJ4FADHQqiRrCP6OETygGNFT.png)
2. Выберите из выпадающего списка подходящую модель. К сожалению, некоторые модели из списка могут не подходить для работы, например эмбеддинговые. Фильтр моделей не настраивается.

3. Определив контекст приглашения, вы можете начать задавать вопросы или использовать предопределенные команды: /test, /review, /explain, /help.
4. Как только вы получите ответ от выбранной LLM, используйте кнопки над кодом, чтобы скопировать примеры кода в буфер обмена или вставить их в свой файл. Или вы можете получить готовый текст для описания работы скрипта в формате Markdown (на английском языке, но вы можете указать в промпте, какой язык использовать в ответе).
## Пример вывода описания
Анализ `/explain` скрипта с помощью модели `qwen2.5-coder-14b-instruct`:
- число строк кода: 500
- контекстное окно модели: 8192 (увеличено с дефолтного 4096)
- токенов:
```json
"usage": {
"prompt_tokens": 6298,
"completion_tokens": 620,
"total_tokens": 6918
}
-
время анализа на карте RTX 5060Ti: 10 секунд
-
качество ответа: более чем устраивает в моем случае. Модель смогла по коду и комментариям составить структурированное описание, что делает этот код.
Спойлер
Конечно! Давайте разберем скрипт на более простые термины, чтобы помочь junior-разработчику понять его функциональность.
Общее описание
Этот скрипт предназначен для обработки PDF- и изображений (JPG/JPEG) с использованием технологии распознавания текста (OCR) через Tesseract. Он проверяет, содержит ли PDF-файл текст, конвертирует его в форматы TIFF и PNG при необходимости, и записывает все действия для детального отчета.
Основные компоненты
-
Определения цветов:
GREENиNCиспользуются для цветного вывода в терминале.
-
Функция помощи (
show_help):- Предоставляет инструкции по использованию, описание, опции и примеры запуска скрипта.
-
Обработка аргументов:
- Скрипт использует цикл
whileс операторамиcaseдля парсинга аргументов командной строки. - Возможны опции: установка DPI, тип сжатия, язык OCR, а также указание сохранять или не сохранять TIFF/PNG/TXT файлы после обработки.
- Скрипт использует цикл
-
Валидация:
- Проверяет, что указанный DPI находится в допустимом диапазоне (72–1200).
- Убедится, что алгоритм сжатия — один из поддерживаемых (
group4,lzw,zip).
-
Настройка логирования:
- Инициализирует файл логов для записи всех действий и выводов.
-
Поиск файлов:
- Использует
findдля поиска PDF- и JPG/JPEG-файлов в указанной директории или в текущей директории, если не указано иное.
- Использует
-
Обработка PDF-файлов:
- Для каждого PDF проверяется наличие текста с помощью
pdftotext. - Если текст найден — логируется как PDF с текстом.
- Если текста нет — PDF конвертируется в TIFF и PNG, затем выполняется OCR на TIFF.
- Для каждого PDF проверяется наличие текста с помощью
-
Обработка изображений:
- Для каждого JPG/JPEG сразу выполняется OCR с помощью Tesseract.
-
Расчет статистики:
- Вычисляются различные статистики: общее количество распознанных символов, максимальное количество символов в одном файле, распределение текста по количеству символов и т.д.
- Вычисляется процент сканированных PDF и средняя скорость распознавания.
-
Генерация итогового отчета:
- Генерируется подробный отчет, включающий все обработанные файлы, статистику и используемые опции.
- Отчет записывается как в терминал, так и в файл логов.
Пример использования
Чтобы запустить скрипт с конкретными опциями:
./work2.sh --dpi 600 --compress lzw --lang rus+eng --no-keep-tiff --no-keep-txt ./docs
```Эта команда устанавливает разрешение DPI в 600, использует сжатие LZW для TIFF-файлов, указывает языки OCR — русский и английский, и не сохраняет TIFF/PNG/TXT-файлы после обработки.
### Заключение
Скрипт — это всесторонний инструмент для массовой обработки PDF- и изображений с возможностями OCR. Он предоставляет подробные логи и статистику, что делает его полезным для автоматизации и анализа задач обработки документов.
Вывод
Очень удобный инструмент, как для поиска оптимальных решений (например, написание функций или справки, визуализации и логирования), так и написания документации.
Схема работы
Полная схема в процессе разработки выглядит так. В следующей статье расскажу о том, как использовать AI Code Review в Gitlab перед запросом на слияние (MR).
graph LR
classDef pclass fill:#f5f5dc
classDef wclass fill:#f96
classDef pmclass fill:#4f7
classDef yclass fill:#ff9
classDef oclass fill:#ffbf00
B(IDEA) -- |Code pre-Review| B1(AI Devoxx):::pclass
B1 -- C(Правка):::wclass
C -- D{Самопроверка}:::oclass
B -- |Твой код идеален| F
F -- H2{Code Review}:::oclass
H2 -.- |На доработку| B1
D -- |Проверено| F(MR):::pmclass
H2 -- E(Merged)