- 如果减少写坏代码的时间呢?
- 好啊,我们把换行符写成猫的样子吧!
图片中,一个头部燃烧着火焰的人坐在电脑前,用铅笔画画,象征着创作枯竭或 burnout。(AI 生成的图片说明)|500x500
目前文档中暂不支持 RAG 和语义功能。
IDE
您觉得这样的功能如何:根据代码自动生成它所实现的功能描述?
如果您使用的是 PyCharm/IDEA,那么您可能可以使用 Devoxx 插件,该插件能够调用 LLM 进行代码审查以及您所要求的任何其他任务。
以下将介绍该插件与 LM Server API 服务的集成方案。
功能特性
- 支持本地和云端语言模型:Anthropic、Groq、Ollama、OpenAI 等…
- 为选定的代码片段提供提示
- 代码审查
- 自动生成代码功能说明
安装步骤
- 安装插件(见下方说明)
- 确保您已启动 Ollama、LMStudio 或 GPT4All
- 更新设置中的提示模板
- 可选:添加云端 LLM 提供商的 API 密钥
- 开始使用插件
请从插件市场安装该插件。如因出口管制法规等原因插件无法安装(开源项目可安装):
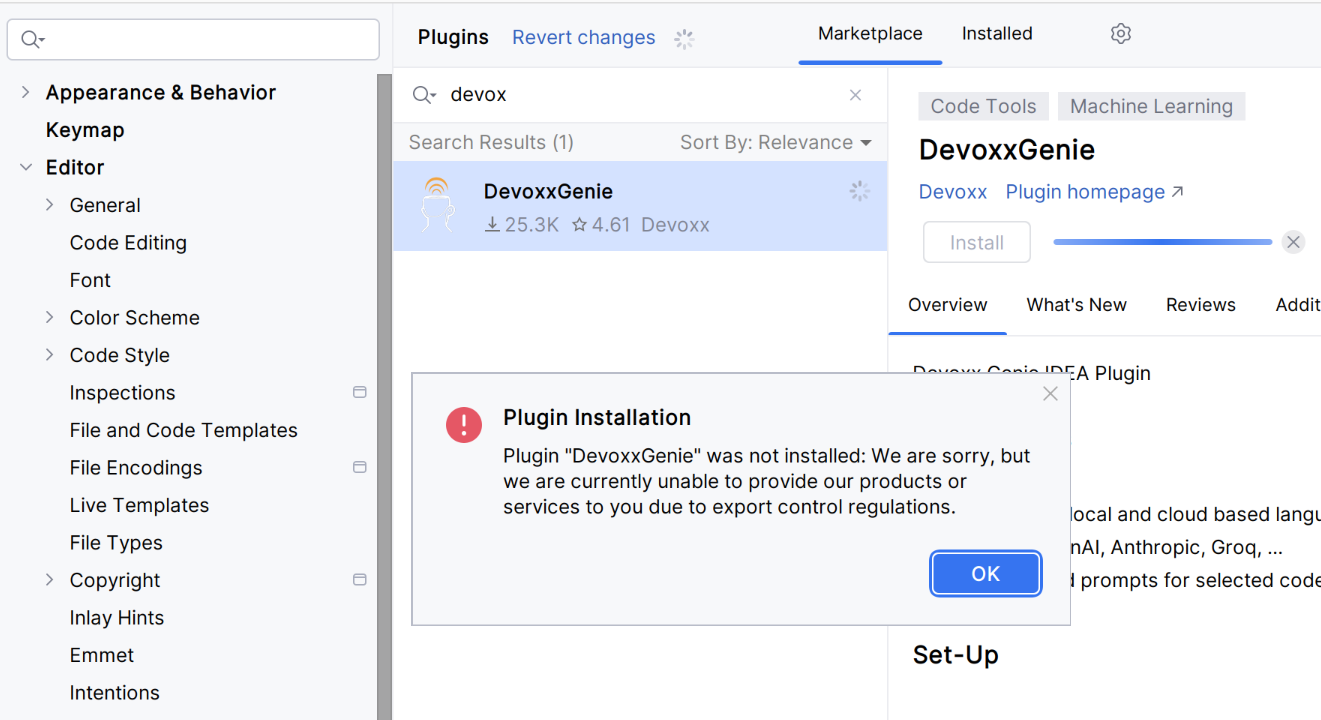
{kind=link}
…您可以从其他电脑复制该插件,或从 GitHub 下载。请注意以下文件夹和文件(Ubuntu 示例):
# 在家目录下
$ find . -iname 'devoxx*'
./.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml
./.cache/JetBrains/PyCharmCE2025.1/DevoxxGenie
./.cache/JetBrains/PyCharmCE2025.1/plugins/DevoxxGenie.zip
./.local/share/JetBrains/PyCharmCE2025.1/DevoxxGenie
```- 将 DevoxxGenie.zip 文件解压到 `~/.local/share/JetBrains/PyCharmCE2025.1` 目录或根据情况解压到 IDEA 目录。在我的情况下,PyCharmCExxx 文件夹需要手动创建,因为原本不存在。
- 将配置文件 `~/.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml` 放置到相应位置。
- 可选操作:您可能需要将插件及其压缩包添加到缓存中。
现在启动 IDE,您应该能在“已安装”标签页中看到插件并带有预设配置:

## 设置
1. 安装插件后,请通过菜单“文件”进入程序设置,以配置 LLM 参数,例如温度、最大输出 token 数量、重试次数和超时设置。如需使用,您还可以添加云 API LLM 密钥。
> DevOps 可为您准备一个 API 服务,作为非加密的 HTTP 服务器。若您处理敏感数据,请勿远程使用,因为流量可能被截获,公开数据将被恶意利用。
说明中提到,在 LM Studio 中正确设置上下文窗口应使用 URL http://localhost:1234/api/v0,但此说法可能有误。实际上,模型加载时需手动将上下文窗口从 4096 扩展至 8192。

在“提示”标签页中,您可以配置系统提示和用户提示。
系统提示是与用户请求一同发送的指令,用于定义任务范围、搜索限制及输出格式。这是关键环节。
请从系统提示中移除以下内容:
The Devoxx Genie is open source and available at GitHub - devoxx/DevoxxGenieIDEAPlugin: DevoxxGenie is a plugin for IntelliJ IDEA that uses local LLM's (Ollama, LMStudio, GPT4All, Jan and Llama.cpp) and Cloud based LLMs to help review, test, explain your project code..
You can follow us on Bluesky @ @devoxxgenie.bsky.social on Bluesky.
所有语言模型均支持 Markdown 格式,因此您可以构建结构化提示,包括列表、子项、代码块等。
> DevOps:默认提示(带限制的请求)定义在文件中:
>
> ```
> ~/.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml
> ```
>
> 模型支持将俄语请求翻译为英语。术语翻译错误或问题表述不准确会严重影响回答质量。请比较以下两个请求:“查找包含说明的页面”与“提供指向该页面的链接”。您认为哪种情况下机器人会提供链接?请严格按您期望的结果(如同向人类提出任务)进行提问。
<br>
2. 在“网络搜索”标签页中,模型可与互联网交互(默认启用)。若您拥有 Google Web Search 个人 API 密钥,可选择使用。
3. RAG 设置详情将在后续补充:

## 使用插件
1. 现在,您可以打开源文件并选择代码片段,或右键单击项目文件将其添加到上下文窗口。
点击按钮 <kbd>Devoxx</kbd>:

2. 从下拉列表中选择合适的模型。遗憾的是,列表中的一些模型可能不适合使用,例如嵌入模型。模型筛选器不可调整。

3. 确定提示上下文后,您可以开始提问或使用预设命令:/test、/review、/explain、/help。
4. 当您从所选 LLM 获得回复后,可以使用代码上方的按钮将示例代码复制到剪贴板或粘贴到您的文件中。或者,您可以获得一个用于描述脚本功能的 Markdown 格式文本(默认为英文,但您可以在提示中指定希望使用哪种语言)。
## 输出示例
使用模型 `qwen2.5-coder-14b-instruct` 分析 `/explain` 脚本:
- 代码行数:500
- 模型上下文窗口:8192(从默认值 4096 增加)
- 令牌数:
```json
"usage": {
"prompt_tokens": 6298,
"completion_tokens": 620,
"total_tokens": 6918
}
-
在 RTX 5060Ti 显卡上的分析时间:10 秒
-
回答质量:在我的情况下非常满意。模型能够根据代码和注释生成结构化的描述,说明了该代码的作用。
剧透
当然!我们来用更简单的语言分解一下这个脚本,帮助初级开发者理解其功能。
概述
该脚本旨在通过使用 Tesseract 进行光学字符识别(OCR)来处理 PDF 和图像文件(JPG/JPEG)。它会检查 PDF 是否包含文本,如无文本则将其转换为 TIFF 和 PNG 格式,然后执行 OCR,并记录所有操作以便详细报告。
主要组件
-
颜色定义:
GREEN和NC用于终端中的彩色输出。
-
帮助函数(
show_help):- 提供使用说明、描述、选项和如何运行脚本的示例。
-
参数解析:
- 脚本使用
while循环与case语句来解析命令行参数。 - 选项包括设置 DPI、压缩类型、OCR 语言,以及是否在处理后保留 TIFF/PNG/TXT 文件。
- 脚本使用
-
验证:
- 检查提供的 DPI 是否在有效范围内(72-1200)。
- 确保压缩算法为支持类型之一(
group4、lzw、zip)。
-
日志设置:
- 初始化日志文件以记录所有操作和输出。
-
文件发现:
- 使用
find命令在指定目录或当前目录(若未提供)中查找 PDF 和 JPG/JPEG 文件。
- 使用
-
PDF 文件处理:
- 对每个 PDF,使用
pdftotext检查是否已包含文本。 - 若发现文本,则记录为包含文本的 PDF。
- 若无文本,则将 PDF 转换为 TIFF 和 PNG 格式,然后对 TIFF 执行 OCR。
- 对每个 PDF,使用
-
图像文件处理:
- 对每个 JPG/JPEG 文件,直接使用 Tesseract 执行 OCR。
-
统计计算:
- 计算各种统计数据,如识别的总字符数、单个文件的最大字符数、按字符数分布的文本情况等。
- 计算扫描 PDF 的百分比和平均识别速度。
-
摘要生成:
- 生成包含所有处理文件、统计信息和所用选项的详细摘要报告。
- 将摘要同时记录到终端和日志文件中。
示例用法
要使用特定选项运行脚本:
./work2.sh --dpi 600 --compress lzw --lang rus+eng --no-keep-tiff --no-keep-txt ./docs
```此命令将DPI设置为600,使用LZW压缩TIFF文件,指定OCR语言为俄语和英语,并在处理后不保留TIFF/PNG/TXT文件。
### 结论
该脚本是一个功能全面的工具,用于批量处理PDF和图像文件并具备OCR能力。它提供详细日志和统计信息,适用于文档处理任务中的自动化与分析。
总结
这是一个非常实用的工具,既可用于寻找最优解决方案(例如编写函数或文档、可视化与日志记录),也可用于编写文档。
工作流程
完整的工作流程正在开发中,下一篇文章将介绍如何在GitLab中使用AI代码审查(AI Code Review)功能,在合并请求(MR)前进行审查。
graph LR
classDef pclass fill:#f5f5dc
classDef wclass fill:#f96
classDef pmclass fill:#4f7
classDef yclass fill:#ff9
classDef oclass fill:#ffbf00
B(IDEA) --|代码预审查|B1(AI Devoxx):::pclass
B1 --|修改|C(修改):::wclass
C --|自检|D{自检}:::oclass
B --|你的代码完美|F
F --|代码审查|H2{Code Review}:::oclass
H2 -.-|需修改|B1
D --|已检查|F(MR):::pmclass
H2 --|已合并|E(Merged)