Weil man damit jetzt keinen Brand mehr löschen kann
Professionelle Verformung: Wenn die Arbeit schlechte Gewohnheiten schafft
Ich habe bereits geschrieben, dass in der IT-Branche mit Hunderten von Wechseln pro Tag nicht häusliche Gewohnheiten den Ansatz zur Arbeit bestimmen, sondern umgekehrt: Die Arbeit formt unsere Gewohnheit, Probleme sofort zu lösen, oft ohne angemessene Analyse der Folgen.
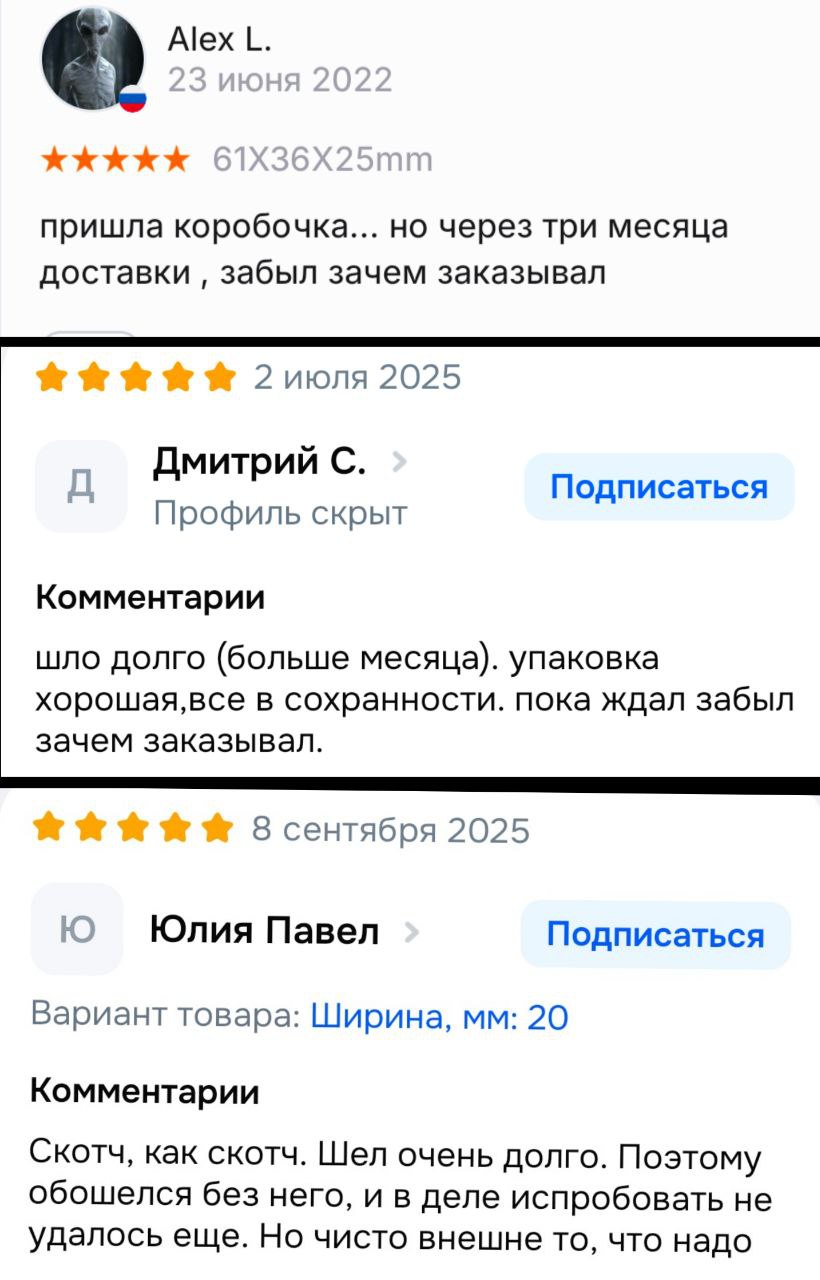
Ich habe für euch einige Beispiele gefunden, wie Menschen dem Impuls zur sofortigen Lösung verfallen – wie bei impulsiven Einkäufen. Die Unglücklichen dachten beim Bestellen, dass das Einkaufen mit einem Klick der einzige Schritt zur Lösung des Problems sei.
Wer hat das gemacht?Stellen Sie sich vor, CTOs und Product Manager großer Unternehmen verhalten sich genau so. Sie bestellen bei DevOps-Teams „Schnell- und einfachlösungen“. Nachdem sie endlich die ersehnte „Schachtel“ mit den neuesten Technologien (Apache Kafka, Objekt-Speicher S3, partitionierte Datenbank, semantischer Suchdienst) erhalten, bemerken sie nicht einmal die unangenehme Wahrheit: Die Produkte kommen ohne Installations-, Konfigurations- und Betriebsanleitung. Es gibt keine Bereitstellungsskripte, keine Skalierbarkeit, keine Leistungsüberwachung. Und das Schlimmste: Niemand hat der DevOps-Team mitgeteilt, dass diese Technologien überhaupt implementiert werden sollen.
Drei Monate nach der Bestellung sind vergangen, doch statt der ersehnten Erleichterung stößt der Manager auf einen neuen Kreis von Problemen. Seine Enttäuschung lässt sich mit den Worten ausdrücken: „Die Schachtel ist angekommen… aber nach drei Monaten Lieferung vergaß ich, warum ich sie bestellt habe.“ Das Streben nach schnellen Erfolgen führt zu operativen Chaos, während das Fehlen strategischen Planens Technologien zu unendlichen Schwierigkeiten macht.## Wir brauchen Kafka für den nächsten Release
Ein Tech-Lead hat einen Artikel auf Habr über „Event-Streaming in Echtzeit“ gelesen, hat zugezogen und gesagt: „Wir brauchen Kafka.“ Ohne Vorschläge, ohne Architektur-Review, ohne DevOps-Beteiligung. Vertraut?
Ja, Kafka ist Open Source. Ja, sie skaliert. Aber fragt jede Team, die sie in Clustern betreibt: Die Reife von Kafka ist nichtlinear – es ist eine Stufenfunktion.
- 0–6 Monate: „Alles funktioniert!“ – Versteckter Partitionen-ungleichgewicht, ungleiche Lastverteilung auf Brokern, unkontrollierte Latenz
- 6–12 Monate: „Warum steigen die Latenzen?“ – Manuelles Neubalancieren, Feuerlöschen, fragmentierte Verantwortung
- 12+ Monate: „Wer ist dafür zuständig? Wie schalten wir das überhaupt aus?“ – „Zombie-Entstehung“ mit unberücksichtigten Kosten für externe Support
Ohne DevOps-ready Automatisierung, Observabilität und Lebenszyklus-Management der gesamten Kafka-Ökosystem liefert Kafka nicht Datenströme, sondern Telegram-Nachrichtenstrom.## S3-kompatibles Speichersystem? Super. Schützen Sie es jetzt
Das Team von Ozon hat Monate damit verbracht, Lusca auf ein S3-kompatibles Speichersystem umzubauen – nicht, weil S3 komplex ist, sondern weil die Umsetzung starker Konsistenz über eventbasierte Systeme, die Verwaltung von Hintergrundprozessen in der Datenbank und das Wiederherstellen von Terabyte-Daten solche Aufgaben erfordern, die tiefgehende Expertise und Zeit benötigen.
Schlimmer noch: Wenn Sie dies in Containern bereitstellen, ohne DevSecOps-Hygiene – ohne Bildscans, ohne Secrets-Management, ohne L7-Netzwerkrichtlinien – dann bauen Sie kein Speichersystem. Sie bauen einen Angriffspunkt und technischen \u003cdel\u003eSchulden\u003c/del\u003e.Brennen.
Datenbank-Sharding: Punkt der keiner Rücknahme mehr möglich ist
Sharden nur, wenn vertikales Skalieren, Query-Optimierung, Caching-Ebenen und Read-Replikationen ausgeschöpft sind. Dies ist das letzte Mittel.
Falsch durchgeführt – erhalten wir „heiße“ Shards, Replication-Verzögerungen und Abfragen zwischen Shards, insbesondere wenn der Sharding-Key falsch gewählt wurde. Fehlende DevOps-Tools für Backup, Monitoring und Umverteilung – tauschen wir Skalierbarkeit gegen Resilienz.
Die Wahrheit ist: Wir können es nicht „de-sharden“. Einmal implementiert, kann man von diesem Punkt nicht mehr zurückkommen, ohne stinkende Probleme.
Und jetzt kommt die echte Problematik – nicht technischer, sondern organisatorischer Natur
Kein Benchmark wird sagen, dass das größte Problem im modernen DevOps nicht Intelligenz, Speicher oder Ausführungszeit ist. Denn es ist die Verzögerung bei Entscheidungen, verursacht durch Probleme mit der Roadmap.In einigen Unternehmen gibt es kein DevOps-Roadmap. In anderen gibt es überhaupt keine. Weil die Strategie den Demo-Verkäufen von „Knien“-Lösungen überlassen wird.
Was führt eine kulturelle reaktive Ausführung dazu?
- Nachdem der CTO den Entwicklungsvertrag unterschrieben hat, erhalten die Ingenieure statt Spezifikationen einen „Pin“: „Automatisiere das auf 100 Servern“ – ohne Dokumentation, ohne verständliche Architektur, ohne Testabdeckung.
- Und drei Monate später: „Warum ist das so langsam? Und warum haben wir das überhaupt gebaut?“
Das ist kein Leadership. Es ist Flucht vor Verantwortung.
DevOps-Teams in reaktiven Organisationen verbrennen ihre gute Absicht, laufen hinter Geistern in Logs und Grafiken her, stellen das gerade, was sie nie entworfen haben, und schützen das, was sie nie besaßen.Wenn etwas kaputtgeht: Die Schuld liegt bei den Menschen, nicht bei den Prozessen. Das ist keine DevOps-Kultur, sondern eine „YasnoOps“-Kommande – also eine „klarwissende“ Mannschaft. Eine reife DevOps-Kultur fragt nicht, wer schuld ist. Sie fragt, was den Ausfall verursacht hat, und verbessert das System – nicht, um den Schuldigen zu finden. In Ihrem Fall ist das System das Fehlen einer Roadmap und das Fehlen der Beteiligung von DevOps in der Entscheidungsfindung.
Russischer Kontext: Geschwindigkeit gegenüber Stabilität
Im Zeitraum 2023–2024 ist der Markt für SaaS in Russland auf mehrere Billionen Rubel angewachsen, doch es handelt sich nicht um einen stabilen, vorhersehbaren Markt, sondern um einen „Schnellkochtopf“. Die Jagd danach, modern auszusehen, zerstört die Grundlagen, die notwendig sind, um modern zu sein.Wir sollten eigentlich in Richtung des von GOSTeh vorgegebenen Weges fortschreiten. Zu standardisiertem Logging, zertifizierten APIs, Monitoring, Anforderungen der FSTEC und Integrität der Lieferkette. Aber wie integrieren wir Standards in eine Architektur, die auf Eile und impulsiven Entscheidungen basiert? Wie gewährleisten wir Sicherheit, wenn DevOps-Teams nicht in das Design involviert waren?
Diese Firma betrachtet die Infrastruktur noch immer als sekundär. Das ist keine Versagen der Ingenieurwissenschaft. Es ist ein Versagen der Erwartungshaltung.
Wie ändert man diese Situation?
Die Lösung liegt in einer Veränderung der Haltung:
- Von „Wir bauen das jetzt für den Verkauf“ → „Bereiten wir uns darauf vor, dieses Projekt in naher Zukunft zu besitzen?“
- Von der Geschwindigkeit der Funktionseinführung → zur Plattformstabilität
- Von DevOps als Feuerwehrmann → zu DevOps als Co-ArchitektGroße Unternehmen haben diesen Weg bereits beschritten. Sie veröffentlichen ihre Roadmaps. Sie verschieben Launches zugunsten der Stabilität. Sie messen die operationale Bereitschaft, nicht nur Release-Daten.
Sie verstehen eine einfache Wahrheit: Geschwindigkeit ohne Kontrolle ist keine Flexibilität. Es ist Drift – und das ist besonders in Enterprise-Software unzulässig, wo staatliche Geheimnisse auf dem Spiel stehen.
Um aus der Krise herauszukommen, ist ein Übergang erforderlich
- Von reaktiver Steuerung zu proaktiver Planung – Entwicklung einer DevOps-Roadmap, Einbeziehung aller Beteiligten in den frühen Phasen.
- Von Ausführenden zu strategischen Partnern – Anerkennung von DevOps als unverzichtbarer Bestandteil des Produktentwicklungsprozesses.
- Von chaotischen Implementierungen zu geplanten Transformationen – schrittweise Einführung von Technologien mit Pilotprojekten und iterativem Aufdecken von Lücken.
- Und dann wird die „Kaufen“-Schaltfläche nicht mehr automatisch gedrückt
 Weil in heutigen Realitäten, insbesondere unter den Bedingungen des GOSTechs, die Vernachlässigung der operativen Reife nicht nur ein Risiko ist, sondern eine strategische Fehler.
Weil in heutigen Realitäten, insbesondere unter den Bedingungen des GOSTechs, die Vernachlässigung der operativen Reife nicht nur ein Risiko ist, sondern eine strategische Fehler.