GitHub
Medium
Начало
Запуск больших языковых моделей (LLM) может требовать значительных вычислительных ресурсов. А когда нужно попробовать разные графические процессоры, то приходится арендовать мощности в облаке.
Управление этими ресурсами вручную занимает много времени, приводит к ошибкам, является сложным в масштабировании и обладает кучей недостатков. Например, нет контроля, сколько каждый сотрудник потратил денег и кто чаще всего забывает выключать виртуалки.
В качестве Lead DevOps я столкнулся с проблемой обеспечения упрощенного способа развертывания, управления и уничтожения экземпляров GPU в RunPod для нашей команды. Нас в первую очередь интересовал инференс с использованием vLLM на разных GPU.
Чтобы решить эту проблему, я разработал конвейер GitLab CI/CD, который автоматизирует весь жизненный цикл графических модулей RunPod прямо из интерфейса GitLab.
Это решение призвано упростить управление ресурсами графического процессора, повысить эффективность рабочего процесса и обеспечить прозрачность процесса развертывания. В этом посте я расскажу вам о настройке и о том, как она работает.
Проблема
Вне зависимости оттого, корректно ли сконфигурирован аккаунт в Runpod, существуют неудобства в плане контроля и биллинга по сотрудникам команды. GPU-вычисления являются дорогостоящими, поэтому контроль, особенно автоматизированный, в этом деле особенно важен.
Стоит ли говорить, что ручной запуск требует больше времени и постоянного внимания?
Человеку свойственно допускать ошибки, особенно в условиях многократных проб.
Есть еще одна проблема (которую пока не удалось гарантированно решить) - это автоматизированное управление скоупом GPU. Ведь параллельная работа с несколькими vLLM явно лучше, чем последовательная.
Решение: Конвейер GitLab CI/CD
В результате исследований у меня получился файл, который я хочу представить - .gitlab-ci.yml. Он использует простые cURL-запросы, с помощью которых создаются Pods и удаляются, настраивается vLLM.
Как это работает
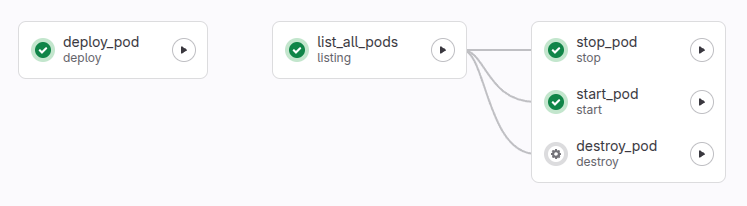
Я разделил код на этапы:
- deploy
- listing
- destroy
- stop
- start
В будущем будут добавлены дополнительные шаги: - отправка писем
- отправка уведомлений в Discourse
Три последних этапа требуют, чтобы был выполнен listing. Поскольку на этом этапе становится известен Pod ID. Его невозможно получить на этапе создания Pod, так как на его развертывание требуется разное время и API отвечает до того, как развертывание завершится. Для этой цели и создан отдельный шаг listing.
Каждый шаг содержит подробное логирование в Gitlab Pipeline. Это должно помочь на ранних этапах и удобно для подключения новых сотрудников.
При запуске нового пайплайна доступно переопределение переменных (иначе вносите переменные через правку кода).
Руководство по установке (краткое)
Важные переменные следует хранить в Gitlab, в разделе Variables в CI проекта. Код обращается к ним. Это такие переменные, как:
- RUNPOD_API_KEY: Ваш API-ключ RunPod
- HG_TOKEN: Ваш токен Hugging Face
- RUNPOD_SSH_PUBLIC_KEYS: Ваши публичные SSH-ключи для доступа к поду (если применимо, разделенные \n, если их несколько)
- RUNPOD_SSH_PRIVATE_KEY: Ваш приватный SSH-ключ, чтобы GitLab Runner мог подключиться к поду
(используйте маскировку чувствительных данных, чтобы они не попадали в лог в открытом виде)
Почему такой подход полезен
Такой подход полезен для:
- Разделения AI-инженеров разных уровней по ролям - один CI подходит для всех
- Каждому сотруднику доступно свое пространство Pipeline с историей
- Легко разделить затраты аккаунта по сотрудникам
- Легко осуществлять контроль запусков и текущих стендов
- Легко хранить различные конфигурации в виде веток
- Удобно быстро развертывать сколько угодно демо-стендов
- Универсальный подход в DevOps - поддержит любой инженер
- Легкая переносимость кода между командами разработки
- Самое главное - 100% совместимость с GitLab workflow при встраивании AI-элементов в архитектуру проекта
Заключение
Эта конфигурация GitLab CI/CD обеспечивает надежный и удобный способ взаимодействия с экземплярами графического процессора RunPod для рабочих Ai-задач. Она устраняет разрыв между практиками DevOps и внедрением моделей искусственного интеллекта. Вы можете найти код и подробные инструкции в репозитории. Как автор, я призываю вас попробовать его, оставить звездочку, если вы сочтете его полезным, и внести свой вклад, если у вас есть идеи по улучшению! Возможно вам было бы интересно посетить мой сайт https://discuss.rabkesov.ru, чтобы узнать больше о моей работе и поучаствовать в дискуссиях.