トークンと料金
AIモデルの基本的な仕組みを理解したうえで、次に「AIモデルがどのように「考え」ているか」および「その使用にかかるコスト」を理解するために、トークンについて解説します。
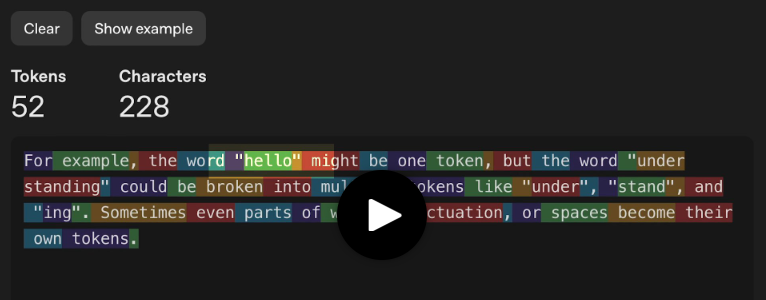
トークンは、AIモデルが実際に理解する「単語」として扱われます。ただし、ここでの「単語」は私たちが普段使っているものとは少し異なります。
コンピュータが「A」の文字を直接理解するのではなく、二進数(1と0)で動作するように、AIモデルも「hello」や「world」といった単語を直接処理するわけではありません。代わりに、すべてをより小さな単位に分割してトークンに分解します。
たとえば、「hello」は1つのトークンとして扱われ、 「understanding」は「under」、「stand」、「ing」の3つのトークンに分割されることがあります。また、単語の一部や記号、スペースなども個別のトークンとして扱われることがあります。
プロンプトを実行し、トークナイザービューを有効化
AIコーディングアシスタントを使用する際、より良いコンテキストを提供するためのヒントは何ですか?簡潔に。
なぜこれが重要か?2つの理由があります:
- 料金はトークン数で算出されます。 あなたは単語や文字数ではなく、トークン数で支払います。
- モデルの速度はトークンで測定されます。 より高速なモデルは、1秒あたりのトークン数(TPS)が高く、ユーザーに返される結果が速いです。
まず、コストについて説明します。これは、AIモデルの使用時にかかる費用を管理する上で重要です。
トークンとは
APIの比喩を続けると、トークンは入力および出力トラフィックを測定し、課金するための単位です。
AIモデルは、2種類のトークンで課金されます:
- 入力トークン — モデルに送信するすべての情報:あなたのクエリと会話の前後のコンテキスト。
- 出力トークン — モデルが返すすべての応答。
出力トークンは、入力トークンの2〜4倍の価格で課金されることが多いです。なぜなら、新しいコンテンツを生成するには、単に送信した内容を処理するよりも多くの計算リソースが必要だからです。
AIモデルがトークンで課金されるため、その理解はコスト管理の鍵となります。これは、サーバーのコストを把握することと同様です。
特に、初期のコンテキスト情報の量(これについては後ほど再び触れますが)を意識的に選択し、モデルにどの程度の詳細な回答を求めるかを明確にすることで、コストをコントロールできます。
ストリーミング応答
ChatGPTや他のAIチャットボットが「リアルタイムで」応答を「打ち出す」ように見えるのは、単なる視覚効果ではなく、モデルが実際にそのように「内部で」動作しているからです。
AIモデルは、トークンを1つずつ順番に生成します。次に生成するトークンを予測し、その予測を使って次のトークンを予測し、そのように繰り返すため、あなたは「単語ごとに」(正確には「トークンごとに」)応答が表示されるように見えます。
応答はストリーミングで提供されます。これは便利です。なぜなら、応答が数分かかるのを待つ必要がなく、モデルが方向を逸れていくようであれば、途中で中断することもできます。
ストリーミング応答に関する正しい主張はどれですか?
ストリーミング応答は、インターフェースのトリックにすぎず、モデルはすべてのテキストを瞬時に生成する。
モデルはトークンを1つずつ生成し、部分的な結果を提供できる。
ストリーミング応答は、出力トークンのコストを削減する。
ストリーミング応答は、中断機能を無効にする。
CheckReset
トークン使用の最適化
AIツールは、基本モデルに送信するトークン数を減らすために、さまざまな手法を採用します。たとえば、繰り返し使用するクエリの一部を自動的にキャッシュしたり、各クエリに含めるコンテキストを管理するように支援したりします。