토큰과 비용
이제 우리는 AI 모델이 어떻게 작동하는지의 기본적인 개념을 이해했으므로, AI 모델이 어떻게 생각하는지를 이해하고, 사용에 따른 비용이 어떻게 책정되는지를 이해하기 위한 핵심 개념인 토큰에 대해 알아보겠습니다.
토큰은 AI 모델이 실제로 이해하는 “단어”로 볼 수 있습니다. 하지만 여기서 중요한 점은, 이 “단어”가 우리가 사용하는 일반적인 단어와 완전히 동일하지는 않다는 것입니다.
컴퓨터가 문자 'A’를 실제로 이해하지 않고 이진 코드(1과 0)로 작동하는 것처럼, AI 모델도 'hello’나 ‘world’ 같은 단어를 직접적으로 처리하지 않습니다. 대신, 모든 것을 더 작은 단위로 분할하여 토큰으로 처리합니다.
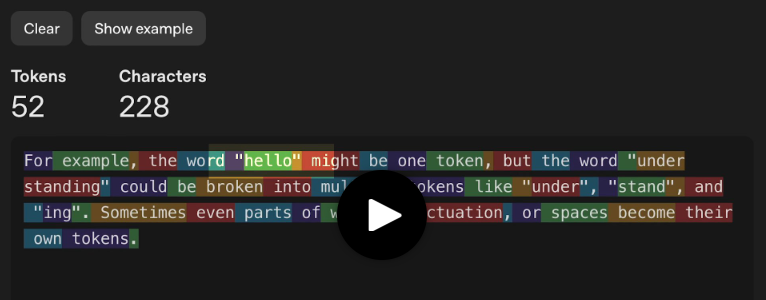
예를 들어, 'hello’는 하나의 토큰일 수 있고, 'understanding’은 ‘under’, ‘stand’, 'ing’으로 나눠서 세 개의 토큰이 될 수 있습니다. 때로는 단어의 일부, 구두점, 공백 등이 각각 독립된 토큰으로 간주됩니다.
프롬프트를 실행하고 토크나이저 보기 활성화
AI 코딩 어시스턴트를 사용할 때 더 나은 컨텍스트를 제공하는 팁은 무엇인가요? 간결하게.
왜 중요한가요? 두 가지 이유 때문입니다:
- 비용은 토큰 단위로 책정됩니다. 단어나 문자 수가 아니라 토큰 수에 따라 비용이 책정됩니다.
- 모델의 속도는 토큰 단위로 측정됩니다. 더 빠른 모델은 더 높은 TPS(토큰/초)를 제공합니다.
먼저 비용에 대해 이야기할 것이며, 이는 AI 모델 사용 시 발생하는 비용을 관리하는 데 영향을 미칩니다.
토큰이란 무엇인가
API의 비유를 이어가면, 토큰은 입력 및 출력 트래픽을 측정하고 요금화하는 단위입니다.
AI 모델은 두 가지 유형의 토큰으로 요금화됩니다:
- 입력 토큰 — 모델에 전송하는 모든 내용: 요청과 대화의 이전 컨텍스트.
- 출력 토큰 — 모델이 당신에게 반환하는 모든 내용.
출력 토큰은 입력 토큰보다 일반적으로 2~4배 더 비쌉니다. 왜냐하면 새로운 콘텐츠 생성은 단순히 입력을 처리하는 것보다 더 많은 계산 자원이 필요하기 때문입니다.
AI 모델이 토큰 기반으로 요금화되므로, 이 개념을 이해하는 것은 비용 관리의 핵심입니다. 이는 서버 비용을 알고 있는 것과 비슷합니다.
입력 컨텍스트의 양을 의식적으로 선택하고, 모델에게 답변을 간결하게 또는 상세하게 요청하는 방식을 선택하는 것이 중요합니다.
스트리밍 방식 응답
ChatGPT와 같은 AI 챗봇이 답변을 실시간으로 'печатать’하는 것처럼 보이는 것을 눈치 채셨나요? 이것은 단순한 시각적 효과가 아니라 모델이 실제로 내부적으로 그렇게 작동합니다.
AI 모델은 토큰을 하나씩 차례로 생성합니다. 다음 토큰을 예측한 후, 이 예측을 바탕으로 다음 토큰을 예측하고, 이 과정을 반복합니다. 따라서 여러분은 단어 하나하나(정확히는 토큰 하나하나)가 차례로 나타나는 것처럼 보입니다.
응답은 스트리밍 방식으로 제공될 수 있습니다. 이는 전체 응답을 기다리는 것(몇 분이 걸릴 수 있음)을 피할 수 있게 해주며, 모델이 편향된 방향으로 답변을 진행할 경우 중단할 수 있습니다.
스트리밍 방식 응답에 대한 다음 중 어떤 진술이 맞습니까?
스트리밍 방식 응답은 단지 인터페이스의 트릭일 뿐이며, 모델은 즉시 전체 텍스트를 생성합니다.
모델은 토큰을 하나씩 생성하며, 부분적인 결과를 제공할 수 있습니다.
스트리밍 방식 응답은 출력 토큰 비용을 낮춥니다.
스트리밍 방식 응답은 중단 기능을 차단합니다.
CheckReset
토큰 사용 최적화
AI 도구는 기본 모델에 전송되는 토큰 수를 줄이기 위한 다양한 방법을 사용합니다. 예를 들어, 반복적으로 사용하는 요청의 일부를 자동으로 캐시하거나, 각 요청에 포함되는 컨텍스트를 관리하는 도움을 줍니다.