Tokens e custo
Agora que já entendemos, de forma geral, como funcionam os modelos de IA, vamos explorar o que ajuda a entender como esses modelos “pensam” e quanto custa seu uso: os tokens.
Tokens podem ser considerados “palavras” que os modelos de IA realmente entendem. Mas há um detalhe: não são exatamente as palavras que usamos nós, humanos.
Assim como seu computador, que na verdade não entende a letra “A”, mas opera com código binário (1 e 0), os modelos de IA também não operam diretamente com palavras como “hello” ou “world”. Em vez disso, eles dividem tudo em partes ainda mais pequenas — tokens.
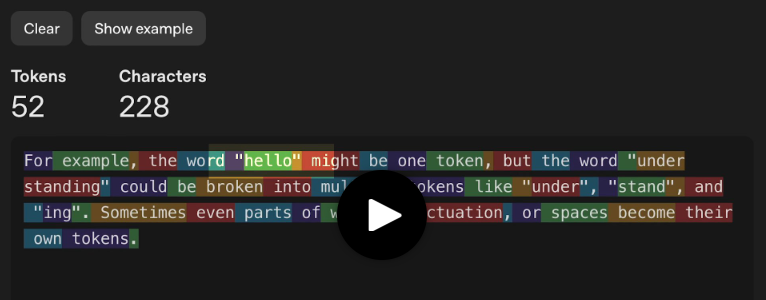
Por exemplo, a palavra “hello” pode ser um único token, enquanto “understanding” pode ser composto por vários: “under”, “stand” e “ing”. Às vezes, até partes de palavras, sinais de pontuação ou espaços em branco se tornam tokens separados.
Execute um prompt e habilite a visualização do tokenizer
Quais são algumas dicas para fornecer melhor contexto ao trabalhar com assistentes de codificação baseados em IA? Seja conciso.
Por que isso é importante? Por duas razões:
- O custo é calculado por tokens. Você paga por tokens, e não por palavras ou símbolos.
- A velocidade dos modelos é medida em tokens. Modelos mais rápidos têm um TPS (tokens por segundo) mais alto, retornando mais tokens ao usuário por segundo.
Vamos falar primeiro sobre o custo, pois isso afeta diretamente seus gastos ao usar modelos de IA.
O que são tokens
Se continuarmos a analogia com APIs, tokens são as unidades pelas quais medimos e tarifamos o tráfego de entrada e saída.
Os modelos de IA tarifam por dois tipos de tokens:
- Tokens de entrada — tudo o que você envia ao modelo: sua solicitação e o contexto anterior da conversa.
- Tokens de saída — tudo o que o modelo retorna para você como resposta.
Os tokens de saída geralmente custam 2 a 4 vezes mais os tokens de entrada, pois a geração de conteúdo novo exige mais recursos computacionais do que apenas processar o que você enviou.
Como os modelos de IA tarifam por tokens, compreendê-los é essencial para controlar os custos. É como saber quanto custa seu servidor.
É importante escolher conscientemente o volume de informações no contexto inicial (voltaremos a isso mais adiante) e como direcionar o modelo para obter respostas mais concisas ou mais detalhadas.
Saída em fluxo
Você já notou como os chatbots de IA, como o ChatGPT, parecem “digitar” respostas em tempo real? Isso não é apenas um efeito visual — os modelos realmente funcionam assim “por baixo dos panos”.
Os modelos de IA geram tokens um por um, sequencialmente. Eles prevêem o próximo token, depois usam essa previsão para prever o próximo, e assim por diante. Por isso, você vê a resposta aparecendo palavra por palavra (ou, mais precisamente, token por token).
As respostas podem ser entregues em fluxo. Isso é conveniente, pois você não precisa esperar o término de toda a resposta, o que pode levar minutos, e pode interromper o modelo se ele começar a se desviar.
Qual afirmação sobre saída em fluxo é correta?
A saída em fluxo é apenas um truque de interface; os modelos geram todo o texto instantaneamente.
Os modelos geram tokens um por um e podem entregar resultados parciais.
A saída em fluxo reduz o custo dos tokens de saída.
A saída em fluxo desativa a possibilidade de interrupção.
CheckReset
Otimização do uso de tokens
Ferramentas de IA frequentemente aplicam métodos para reduzir o número de tokens enviados às modelos base. Por exemplo, automaticamente cacheiam partes do seu prompt que você usa repetidamente, ou ajudam a gerenciar o contexto incluído em cada solicitação.