Токены и стоимость
Теперь, когда мы в общих чертах понимаем, как работают модели ИИ, разберёмся с тем, что поможет понять и как эти модели «думают», и сколько стоит их использование: токены.
Токены можно считать «словами», которые модели ИИ реально понимают. Но есть нюанс: это не совсем те слова, которыми пользуемся мы с вами.
Как и ваш компьютер, который на самом деле не понимает букву «A», а работает с двоичным кодом (1 и 0), модели ИИ тоже не оперируют напрямую словами вроде «hello» или «world». Вместо этого они разбивают всё на более мелкие части — токены.
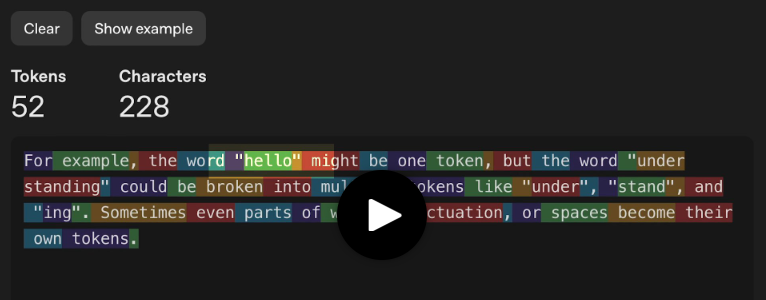
Например, слово «hello» может быть одним токеном, а «understanding» — несколькими: «under», «stand» и «ing». Иногда даже части слов, знаки препинания или пробелы становятся отдельными токенами.
Run a prompt and enable tokenizer viewStart
What are some tips for providing better context when working with AI coding assistants? Be concise.
Почему это важно? По двум причинам:
- Оплата рассчитывается по токенам. Вы платите за токены, а не за слова или символы.
- Скорость моделей измеряется в токенах. Более быстрые модели имеют более высокий TPS — tokens per second (токенов в секунду), возвращаемых пользователю.
Сначала поговорим о стоимости, поскольку это влияет на ваши расходы при использовании моделей ИИ.
Что такое токены
Если продолжить аналогию с API, то токены — это единицы, которыми мы измеряем и тарифицируем входящий и исходящий трафик.
Модели ИИ тарифицируют по двум типам токенов:
- Входные токены — всё, что вы отправляете модели: ваш запрос и предыдущий контекст беседы.
- Выходные токены — всё, что модель возвращает вам в ответ.
Выходные токены обычно стоят в 2–4 раза дороже входных, потому что генерация нового содержимого требует больше вычислительных ресурсов, чем просто обработка того, что вы отправили.
Поскольку модели ИИ тарифицируют по токенам, их понимание — ключ к управлению затратами. Это как знать, сколько стоит ваш сервер.
Важно осознанно выбирать объём информации в исходном контексте (к этому мы вернёмся далее) и то, как направлять модель, чтобы ответы были либо лаконичными, либо подробными.
Потоковая выдача ответов
Вы замечали, как ChatGPT и другие ИИ‑чат-боты будто «печатают» ответы в реальном времени? Это не просто визуальный эффект — модели действительно так работают «под капотом».
ИИ‑модели генерируют токены по одному, последовательно. Они предсказывают следующий токен, затем используют это предсказание, чтобы предсказать следующий за ним, и так далее. Поэтому вы видите, как ответ появляется слово за словом (точнее, токен за токеном).
Ответы могут поступать потоково. Это удобно, потому что не нужно ждать завершения всего ответа, что может занять минуты, и вы можете прервать модель, если она начинает уходить в сторону.
Какое утверждение о потоковой выдаче верно?
Потоковая выдача — это лишь трюк интерфейса; модели мгновенно генерируют весь текст.
Модели генерируют токены по одному и могут выдавать частичные результаты.
Потоковая выдача снижает стоимость выходных токенов.
Потоковая выдача отключает возможность прерывания.
CheckReset
Оптимизация использования токенов
Инструменты ИИ часто применяют методы для сокращения числа токенов, отправляемых в базовые модели. Например, автоматически кэшируют части вашего запроса, которые вы используете неоднократно, или помогают управлять контекстом, включаемым в каждый запрос.