- Et si on réduisait le temps passé à écrire du mauvais code ?
- Oui, et faisons des retours à la ligne en forme de chat !

L’instruction ne prend pas encore en charge RAG ni la sémantique.
IDE
Et si vous pouviez, à partir du code, générer une description de ce qu’il fait ?
Si vous travaillez dans PyCharm/IDEA, vous pouvez avoir accès au plugin Devoxx, capable d’interagir avec un modèle de langage LLM pour des revues de code et tout ce que vous lui demandez.
Voici un exemple de configuration du plugin avec un service API de LM Server.
Fonctionnalités
- Support des modèles linguistiques locaux et cloud : Anthropic, Groq, Ollama, OpenAI, etc.
- Suggestions pour les fragments de code sélectionnés
- Revue de code
- Génération de descriptions de ce que fait le code.
Plan d’installation
- Installez le plugin (voir ci-dessous)
- Assurez-vous que Ollama, LMStudio ou GPT4All sont en cours d’exécution
- Mettez à jour les prompts dans les paramètres
- (Facultatif) Ajoutez vos clés API pour les fournisseurs cloud de LLM
- Commencez à utiliser le plugin
Installez le plugin depuis le marketplace. Si, pour une raison quelconque, le plugin ne peut pas être installé (en raison de réglementations de contrôle des exportations, open-source oui) :
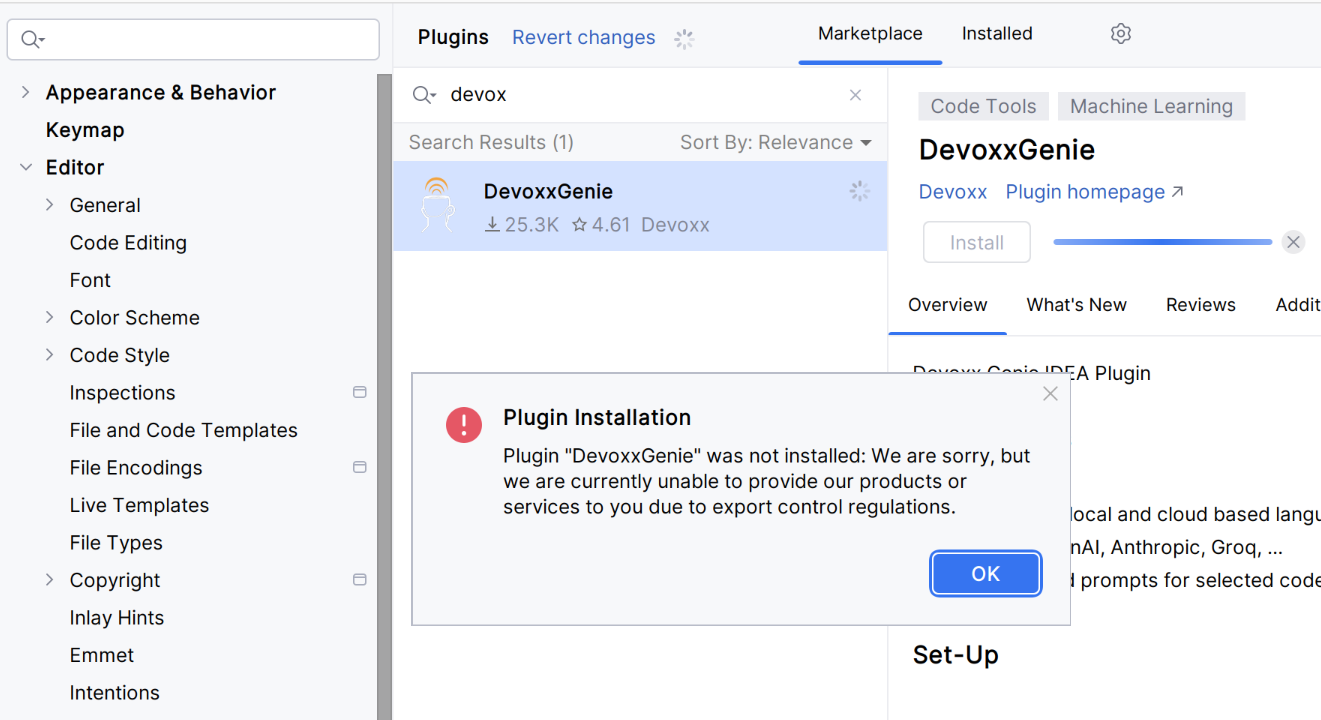
… vous pouvez copier ce plugin depuis un autre ordinateur ou le télécharger depuis GitHub. Veuillez noter les dossiers et fichiers suivants (exemple sur Ubuntu) :
# dans le répertoire personnel
$ find . -iname 'devoxx*'
./.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml
./.cache/JetBrains/PyCharmCE2025.1/DevoxxGenie
./.cache/JetBrains/PyCharmCE2025.1/plugins/DevoxxGenie.zip
./.local/share/JetBrains/PyCharmCE2025.1/DevoxxGenie
```- Décompressez le fichier `DevoxxGenie.zip` dans le dossier `~/.local/share/JetBrains/PyCharmCE2025.1` ou dans l'IDE selon le cas. Dans mon cas, j'ai dû créer manuellement le dossier `PyCharmCExxx` car il n'existait pas.
- Placez le fichier de configuration `~/.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml`.
- Optionnel. Vous pourriez avoir besoin d’ajouter le plugin et son archive au cache.
Lancez maintenant l’IDE, et vous devriez voir le plugin avec les paramètres prêts (sur l’onglet « Installed ») :

## Configuration
1. Après l’installation du plugin, allez dans les paramètres du programme (via le menu File) pour configurer les paramètres de l’LLM, tels que la température, le nombre maximal de tokens de sortie, les tentatives répétées et les délais. Vous pouvez également ajouter des clés API cloud LLM si vous souhaitez les utiliser.
> DevOps : vous pouvez préparer un service API qui fonctionne comme un serveur HTTP non sécurisé. Ne l’utilisez pas à distance si vous travaillez avec des données sensibles, car le trafic peut être intercepté et les données ouvertes seront utilisées par des attaquants.
Il est mentionné que pour définir correctement la fenêtre contextuelle dans LM Studio, il faut utiliser l’URL `http://localhost:1234/api/v0`, ce qui semble incorrect. La fenêtre contextuelle du modèle doit être augmentée lors de son chargement (4096 → 8192).

Sur l’onglet « Prompts », vous pouvez configurer le prompt système et les requêtes utilisateur.
Le prompt système est une requête envoyée avec la requête utilisateur et définit le domaine de tâche, les limites de recherche et le format de la réponse. C’est un point critique.
Supprimez les lignes suivantes du prompt système :
The Devoxx Genie is open source and available at GitHub - devoxx/DevoxxGenieIDEAPlugin: DevoxxGenie is a plugin for IntelliJ IDEA that uses local LLM's (Ollama, LMStudio, GPT4All, Jan and Llama.cpp) and Cloud based LLMs to help review, test, explain your project code..
You can follow us on Bluesky @ @devoxxgenie.bsky.social on Bluesky.
Toutes les modèles de langues comprennent la syntaxe Markdown, donc vous pouvez créer des prompts structurés avec des listes, des sous-points, des blocs de code.
> DevOps : les prompts par défaut (requêtes avec contraintes) sont définis dans le fichier
>
> ```
> ~/.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml
> ```
>
> Les modèles peuvent traduire les requêtes en russe en anglais. Une mauvaise traduction des termes peut fortement affecter la qualité de la réponse, tout comme une question imprecise. Comparez les requêtes : « trouvez la page avec l’instruction » et « fournissez un lien vers la page ». Quel cas pensez-vous que le bot fournira le lien ? Demandez toujours exactement ce que vous attendez (comme dans la formulation de la tâche à un humain).
<br>
2. Sur l’onglet « Web search », vous trouverez l’option d’interaction du modèle avec Internet (activée par défaut). Si vous avez une clé API Google Web Search personnelle, vous pouvez l’utiliser.
3. Les détails de configuration RAG seront ajoutés ultérieurement :

## Utilisation du plugin
1. Ouvrez maintenant le fichier source et sélectionnez un fragment de code, ou cliquez avec le bouton droit sur le fichier du projet pour l’ajouter au contexte de la fenêtre.
Appuyez sur le bouton `<kbd>Devoxx</kbd>` :

2. Choisissez le modèle approprié dans la liste déroulante. Malheureusement, certains modèles de la liste peuvent ne pas convenir à l’utilisation, par exemple les modèles d’embedding. Le filtre de modèles n’est pas configurable.

3. Une fois le contexte de l’invitation défini, vous pouvez commencer à poser des questions ou utiliser les commandes prédéfinies : /test, /review, /explain, /help.
4. Une fois que vous avez reçu la réponse de la LLM choisie, utilisez les boutons au-dessus du code pour copier les exemples de code dans le presse-papiers ou les insérer dans votre fichier. Ou vous pouvez obtenir un texte prêt à l’emploi pour décrire le fonctionnement du script au format Markdown (en anglais, mais vous pouvez spécifier dans le prompt quel langage utiliser dans la réponse).
## Exemple de sortie de description
Analyse du script `/explain` avec le modèle `qwen2.5-coder-14b-instruct` :
- Nombre de lignes de code : 500
- Contexte de la fenêtre de la modèle : 8192 (augmenté par défaut de 4096)
- Tokens :
```json
"usage": {
"prompt_tokens": 6298,
"completion_tokens": 620,
"total_tokens": 6918
}
-
Temps d’analyse sur la carte RTX 5060Ti : 10 secondes
-
Qualité de la réponse : plus qu’acceptable dans mon cas. Le modèle a réussi à produire une description structurée du code à partir du code et des commentaires, ce qui rend ce code compréhensible.
Spoiler
Bien sûr ! Examinons ce script en termes plus simples pour aider un développeur junior à comprendre sa fonctionnalité.
Vue d’ensemble
Ce script est conçu pour traiter les fichiers PDF et images (JPG/JPEG) en effectuant la reconnaissance optique des caractères (OCR) à l’aide de Tesseract. Il vérifie si le PDF contient déjà du texte, le convertit en formats TIFF et PNG si nécessaire, et enregistre toutes les actions pour un rapport détaillé.
Composants clés
-
Définitions de couleurs :
GREENetNCsont utilisés pour l’affichage coloré dans le terminal.
-
Fonction d’aide (
show_help) :- Fournit des instructions d’utilisation, une description, des options et des exemples de la façon de lancer le script.
-
Analyse des arguments :
- Le script utilise une boucle
whileavec des instructionscasepour analyser les arguments en ligne de commande. - Les options incluent la définition de la résolution DPI, le type de compression, la langue OCR, et la décision de conserver ou non les fichiers TIFF/PNG/TXT après le traitement.
- Le script utilise une boucle
-
Validation :
- Vérifie si la résolution DPI fournie est dans une plage valide (72-1200).
- Assure que l’algorithme de compression est l’un des types supportés (
group4,lzw,zip).
-
Configuration du journal :
- Initialise un fichier de journal pour enregistrer toutes les actions et sorties.
-
Découverte des fichiers :
- Utilise
findpour localiser les fichiers PDF et JPG/JPEG dans le répertoire spécifié ou dans le répertoire courant s’il n’est pas fourni.
- Utilise
-
Traitement des fichiers PDF :
- Pour chaque PDF, il vérifie s’il contient déjà du texte à l’aide de
pdftotext. - S’il y a du texte, il enregistre le fichier comme PDF contenant du texte.
- S’il n’y a pas de texte, il convertit le PDF en formats TIFF et PNG, puis effectue l’OCR sur le TIFF.
- Pour chaque PDF, il vérifie s’il contient déjà du texte à l’aide de
-
Traitement des fichiers images :
- Pour chaque JPG/JPEG, il effectue directement l’OCR à l’aide de Tesseract.
-
Calcul des statistiques :
- Calcule diverses statistiques telles que le nombre total de caractères reconnus, le nombre maximum de caractères dans un seul fichier, la répartition du texte par nombre de caractères, etc.
- Calcule le pourcentage de PDF numérisés et la vitesse moyenne de reconnaissance.
-
Génération du résumé :
- Génère un rapport détaillé incluant tous les fichiers traités, les statistiques et les options utilisées.
- Enregistre ce résumé à la fois dans le terminal et dans le fichier de journal.Ce commandement définit la résolution DPI à 600, utilise la compression LZW pour les fichiers TIFF, spécifie les langues russe et anglaise pour la reconnaissance optique des caractères (OCR), et ne conserve pas les fichiers TIFF/PNG/TXT après le traitement.
Conclusion
Ce script est un outil complet pour le traitement en masse de PDFs et d’images avec des capacités OCR. Il fournit un journal détaillé et des statistiques, ce qui le rend utile pour l’automatisation et l’analyse dans les tâches de traitement de documents.
Conclusion
Un outil très pratique, aussi bien pour la recherche d’optimisations (par exemple, rédaction de fonctions ou de documentation, visualisation et journalisation), que pour la rédaction de documentation.
Schéma de fonctionnement
Le schéma complet en cours de développement ressemble à ceci. Dans l’article suivant, je vais expliquer comment utiliser l’analyse de code par IA dans GitLab avant la demande de fusion (MR).
graph LR
classDef pclass fill:#f5f5dc
classDef wclass fill:#f96
classDef pmclass fill:#4f7
classDef yclass fill:#ff9
classDef oclass fill:#ffbf00
B(IDEA) --|Pré-revue de code|B1(AI Devoxx):::pclass
B1 -- C(Édition):::wclass
C -- D{Auto-vérification}:::oclass
B --|Votre code est parfait|F
F -- H2{Code Review}:::oclass
H2 -.-|À améliorer|B1
D --|Validé|F(MR):::pmclass
H2 -- E(Merged)