- E se riducessimo il tempo di scrittura di codice cattivo?
- Sì, e facciamo i ritorni a capo a forma di gatto!

L’istruzione attuale non supporta ancora RAG e la semantica.
IDE
E se vi piacesse questa funzionalità: generare una descrizione del codice su cosa fa?
Se lavorate in PyCharm/IDEA, potrebbe essere disponibile il plugin Devoxx, in grado di interagire con i modelli linguistici di grandi dimensioni (LLM) per revisioni del codice e qualsiasi altra richiesta.
Di seguito viene esaminato il caso di integrazione del plugin con il servizio API di LM Server.
Funzionalità
- Supporto per modelli linguistici locali e cloud: Anthropic, Groq, Ollama, OpenAI, …
- Suggerimenti per frammenti di codice selezionati
- Revisione del codice
- Generazione di descrizioni su cosa fa il codice
Piano di installazione
- Installare il plugin (vedi sotto)
- Assicurarsi che siano attivi Ollama, LMStudio o GPT4All
- Aggiornare i prompt nelle impostazioni
- (Opzionale): Aggiungere chiavi API per i fornitori cloud di LLM
- Iniziare a usare il plugin
Installare il plugin dal marketplace. Se per qualche motivo il plugin non può essere installato (a causa di regolamenti di controllo delle esportazioni, open source sì):
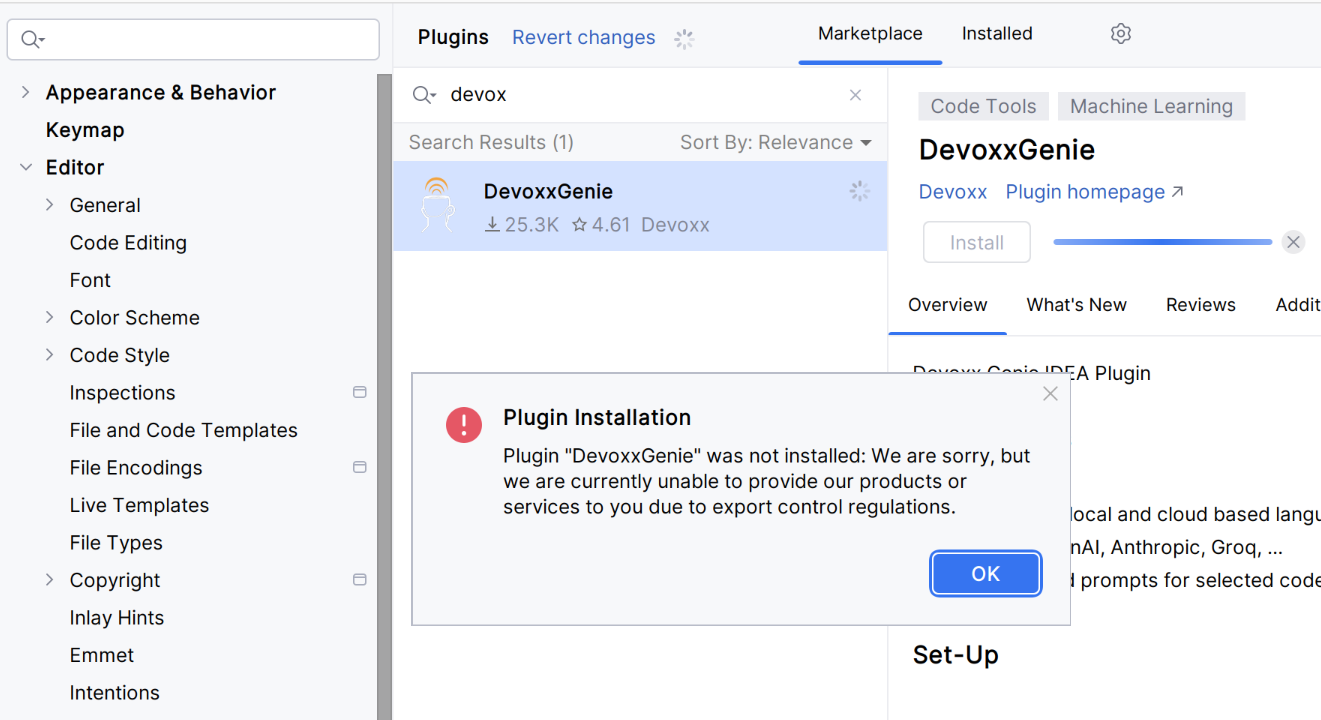
…potete copiare il plugin da un altro computer o dal GitHub. Attenzione alle seguenti cartelle e file (esempio su Ubuntu):
# nella cartella home
$ find . -iname 'devoxx*'
./.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml
./.cache/JetBrains/PyCharmCE2025.1/DevoxxGenie
./.cache/JetBrains/PyCharmCE2025.1/plugins/DevoxxGenie.zip
./.local/share/JetBrains/PyCharmCE2025.1/DevoxxGenie
```- Estrae il file DevoxxGenie.zip nella cartella `~/.local/share/JetBrains/PyCharmCE2025.1` o nell'IDE, a seconda del caso. Nel mio caso, la cartella PyCharmCExxx doveva essere creata manualmente, poiché non esisteva.
- Pubblica il file di configurazione `~/.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml`.
- Opzionale. Potrebbe essere necessario aggiungere il plugin e il suo archivio al cache.
Ora avvia l'IDE e dovresti vedere il plugin con le impostazioni preconfigurate (sull'anteprima "Installed"):

## Configurazione
1. Dopo l'installazione del plugin, vai alle impostazioni del programma (tramite il menu File) per configurare i parametri dell'LLM, come temperatura, numero massimo di token di output, tentativi ripetuti e timeout. Se lo desideri, puoi anche aggiungere chiavi API cloud LLM per usarle.
> DevOps: puoi preparare un servizio API che funzioni come un server HTTP non protetto. Non utilizzarlo remotamente se stai lavorando con dati sensibili, poiché il traffico può essere intercettato e i dati aperti potrebbero essere sfruttati da malintenzionati.
Si dice che per determinare correttamente la finestra di contesto in LM Studio sia necessario usare l'URL http://localhost:1234/api/v0, ma questo sembra errato. La finestra di contesto del modello deve essere aumentata durante il caricamento (4096 → 8192).

Nella scheda Prompts puoi configurare il prompt di sistema e i prompt personalizzati.
Il prompt di sistema è una richiesta inviata insieme alla richiesta utente e definisce l'ambito delle attività, i limiti di ricerca e il formato delle informazioni fornite. È un punto cruciale.
Rimuovi dal prompt di sistema le righe seguenti:
The Devoxx Genie is open source and available at GitHub - devoxx/DevoxxGenieIDEAPlugin: DevoxxGenie is a plugin for IntelliJ IDEA that uses local LLM's (Ollama, LMStudio, GPT4All, Jan and Llama.cpp) and Cloud based LLMs to help review, test, explain your project code..
You can follow us on Bluesky @ @devoxxgenie.bsky.social on Bluesky.
Tutte le modelli linguistici comprendono la formattazione Markdown, quindi puoi creare prompt strutturati con elenchi, sottopunti e blocchi di codice.
> DevOps: i prompt predefiniti (richieste con vincoli) sono definiti nel file
>
> ```
> ~/.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml
> ```
>
> Le modelli hanno la capacità di tradurre richieste in russo in inglese. Una traduzione imprecisa dei termini può influire notevolmente sulla qualità della risposta, così come una domanda imprecisa. Confronta le richieste: "trova la pagina con l'istruzione" e "fornisci un link alla pagina". In quale caso il bot fornirà il link? Chiedi esattamente ciò che aspetti (esattamente come si farebbe a una persona).
<br>
2. Nella scheda Web search c'è un'opzione per l'interazione del modello con internet (attiva di default). Se hai una chiave personale di Google Web Search, puoi usarla.
3. Dettagli sulla configurazione RAG verranno aggiunti in seguito:

## Uso del plugin
1. Ora, apri il file sorgente e seleziona un frammento di codice, oppure fai clic con il tasto destro sul file del progetto per aggiungerlo al contesto della finestra.
Premi il pulsante <kbd>Devoxx</kbd>:

2. Selezionate dal menu a discesa il modello appropriato. Purtroppo, alcuni modelli nell'elenco potrebbero non essere adatti all'uso, ad esempio quelli embedding. Il filtro dei modelli non è personalizzabile.

3. Dopo aver definito il contesto dell'invito, potete iniziare a porre domande o utilizzare i comandi predefiniti: /test, /review, /explain, /help.
4. Non appena ricevete la risposta dalla LLM selezionata, utilizzate i pulsanti sopra il codice per copiare gli esempi di codice negli appunti o incollarli nel vostro file. Oppure potete ottenere un testo pronto per la descrizione del funzionamento dello script nel formato Markdown (in inglese, ma potete specificare nel prompt quale lingua utilizzare nella risposta).
## Esempio di output della descrizione
Analisi dello script `/explain` con il modello `qwen2.5-coder-14b-instruct`:
- Numero di righe di codice: 500
- Contesto della finestra del modello: 8192 (aumentato dal valore predefinito di 4096)
- Token:
```json
"usage": {
"prompt_tokens": 6298,
"completion_tokens": 620,
"total_tokens": 6918
}
-
Tempo di analisi sulla scheda RTX 5060Ti: 10 secondi
-
Qualità della risposta: più che soddisfacente nel mio caso. Il modello è riuscito a creare una descrizione strutturata del codice, basandosi sul codice e sui commenti, rendendo così il codice comprensibile.
Spoiler
Certamente! Analizziamo lo script in termini più semplici per aiutare uno sviluppatore junior a comprendere la sua funzionalità.
Panoramica
Questo script è progettato per elaborare file PDF e immagini (JPG/JPEG) eseguendo l’OCR (Optical Character Recognition) tramite Tesseract. Verifica se il PDF contiene testo, lo converte in formati TIFF e PNG se necessario, e registra tutte le azioni per un report dettagliato.
Componenti chiave
-
Definizioni di colore:
GREENeNCvengono utilizzati per l’output colorato nel terminale.
-
Funzione di aiuto (
show_help):- Fornisce istruzioni per l’uso, descrizione, opzioni e esempi su come eseguire lo script.
-
Analisi degli argomenti:
- Lo script utilizza un ciclo
whilecon dichiarazionicaseper analizzare gli argomenti della riga di comando. - Le opzioni includono la configurazione del DPI, del tipo di compressione, della lingua OCR e se mantenere o meno i file TIFF/PNG/TXT dopo l’elaborazione.
- Lo script utilizza un ciclo
-
Validazione:
- Verifica che il DPI fornito sia all’interno di un intervallo valido (72-1200).
- Assicura che l’algoritmo di compressione sia uno dei tipi supportati (
group4,lzw,zip).
-
Configurazione del logging:
- Inizializza un file di log per registrare tutte le azioni e gli output.
-
Ricerca dei file:
- Utilizza
findper individuare i file PDF e JPG/JPEG nella directory specificata o nella directory corrente se non viene fornita alcuna.
- Utilizza
-
Elaborazione dei file PDF:
- Per ogni PDF, verifica se contiene già testo utilizzando
pdftotext. - Se il testo è già presente, registra il file come PDF contenente testo.
- Se non è presente testo, converte il PDF in formati TIFF e PNG, quindi esegue l’OCR sul TIFF.
- Per ogni PDF, verifica se contiene già testo utilizzando
-
Elaborazione dei file immagine:
- Per ogni JPG/JPEG, esegue direttamente l’OCR tramite Tesseract.
-
Calcolo delle statistiche:
- Calcola varie statistiche, come il numero totale di caratteri riconosciuti, il massimo numero di caratteri in un singolo file, la distribuzione del testo in base al numero di caratteri, ecc.
- Calcola la percentuale di PDF scansionati e la velocità media di riconoscimento.
-
Generazione del riassunto:
- Genera un riassunto dettagliato che include tutti i file elaborati, le statistiche e le opzioni utilizzate.
- Registra questo riassunto sia nel terminale che nel file di log.Questo comando imposta il DPI a 600, utilizza la compressione LZW per i file TIFF, specifica le lingue russo e inglese per l’OCR e non conserva i file TIFF/PNG/TXT dopo il processo.
Conclusione
Lo script è uno strumento completo per il processamento batch di PDF e immagini con capacità OCR. Fornisce log e statistiche dettagliate, rendendolo utile per l’automazione e l’analisi in compiti di elaborazione documenti.
Conclusione
Un’ottima utility sia per la ricerca di soluzioni ottimali (ad esempio, scrittura di funzioni o documentazione, visualizzazione e logging), sia per la creazione di documentazione.
Schema di funzionamento
La completa architettura in fase di sviluppo appare così. Nell’articolo successivo spiegherò come utilizzare il Code Review AI in GitLab prima della richiesta di merge (MR).
graph LR
classDef pclass fill:#f5f5dc
classDef wclass fill:#f96
classDef pmclass fill:#4f7
classDef yclass fill:#ff9
classDef oclass fill:#ffbf00
B(IDEA) --|Code pre-Review| B1(AI Devoxx):::pclass
B1 -- C(Revisione):::wclass
C -- D{Auto-verifica}:::oclass
B --|Il tuo codice è perfetto| F
F -- H2{Code Review}:::oclass
H2 -.-|Da rivedere| B1
D --|Verificato| F(MR):::pmclass
H2 -- E(Merged)