Tokens und Kosten
Nun, da wir bereits eine allgemeine Vorstellung davon haben, wie KI-Modelle funktionieren, beschäftigen wir uns nun mit dem, was Ihnen helfen wird, wie diese Modelle „denken“, und wie viel ihre Nutzung kostet: Tokens.
Tokens können als „Wörter“ verstanden werden, die KI-Modelle tatsächlich verstehen. Es gibt jedoch einen Nuance: Es sind nicht genau jene Wörter, die wir selbst verwenden.
Wie Ihr Computer, der in Wirklichkeit den Buchstaben „A“ nicht versteht, sondern mit Binärcode (1 und 0) arbeitet, arbeiten KI-Modelle ebenfalls nicht direkt mit Wörtern wie „hello“ oder „world“. Stattdessen zerlegen sie alles in kleinere Teile – Tokens.
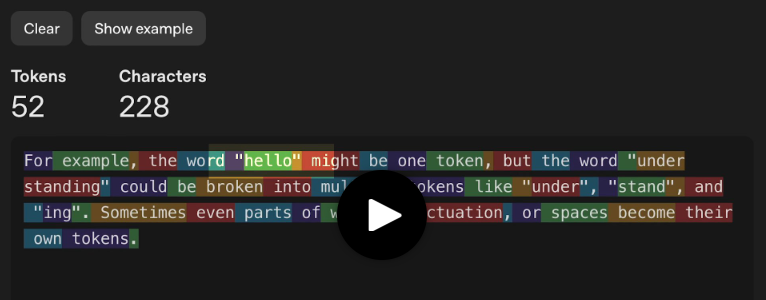
Zum Beispiel kann das Wort „hello“ ein Token sein, während „understanding“ mehrere Tokens sein kann: „under“, „stand“ und „ing“. Manchmal werden sogar Teile von Wörtern, Satzzeichen oder Leerzeichen als separate Tokens betrachtet.
Prompt ausführen und Tokenisierungsansicht aktivieren
Was sind einige Tipps, um besseren Kontext bei der Arbeit mit KI-Coding-Assistenz zu liefern? Seien Sie kurz.
Warum ist das wichtig? Aus zwei Gründen:
- Die Kosten werden nach Tokens berechnet. Sie zahlen für Tokens, nicht für Wörter oder Zeichen.
- Die Geschwindigkeit der Modelle wird in Tokens gemessen. Schnellere Modelle haben eine höhere TPS – tokens per second (Tokens pro Sekunde), die an den Benutzer zurückgegeben werden.
Zuerst sprechen wir über die Kosten, da dies Ihre Ausgaben beim Einsatz von KI-Modellen beeinflusst.
Was sind Tokens
Wenn man die Analogie mit einem API fortsetzt, sind Tokens die Einheiten, mit denen wir Eingangs- und Ausgangsdaten messen und abrechnen.
KI-Modelle berechnen nach zwei Arten von Tokens:
- Eingangstokens – alles, was Sie dem Modell senden: Ihre Anfrage und der vorherige Gesprächskontext.
- Ausgangstokens – alles, was das Modell Ihnen als Antwort zurückgibt.
Ausgangstokens kosten normalerweise 2–4-mal mehr als Eingangstokens, da die Generierung neuer Inhalte mehr Rechenressourcen erfordert als die einfache Verarbeitung dessen, was Sie gesendet haben.
Da KI-Modelle nach Tokens abrechnen, ist ihr Verständnis entscheidend für die Kostensteuerung. Es ist wie das Wissen, wie viel Ihr Server kostet.
Es ist wichtig, bewusst den Umfang der Informationen im ursprünglichen Kontext zu wählen (dazu kommen wir später zurück) und wie Sie die Modelle lenken, damit Antworten entweder knapp oder detailliert sind.
Streamende Antwortausgabe
Haben Sie bemerkt, wie ChatGPT und andere KI-Chats „in Echtzeit“ Antworten „schreiben“? Es ist kein bloßer visueller Effekt – die Modelle arbeiten tatsächlich so „unter der Haube“.
KI-Modelle generieren Tokens nacheinander, ein nach dem anderen. Sie prognostizieren den nächsten Token, nutzen dann diese Vorhersage, um den nächsten zu prognostizieren und so weiter. Deshalb sehen Sie, wie die Antwort Wort für Wort (genauer: Token für Token) erscheint.
Antworten können streamend geliefert werden. Das ist praktisch, da man nicht auf das Ende der gesamten Antwort warten muss, was Minuten dauern kann, und man die Modelle unterbrechen kann, wenn sie abweichen.
Welche Aussage über die streamende Antwortausgabe ist korrekt?
Die streamende Antwortausgabe ist nur ein Interface-Trick; Modelle generieren den gesamten Text sofort.
Modelle generieren Tokens nacheinander und können teilweise Ergebnisse liefern.
Die streamende Antwortausgabe senkt die Kosten für Ausgangstokens.
Die streamende Antwortausgabe deaktiviert die Möglichkeit zum Unterbrechen.
CheckReset
Optimierung der Token-Nutzung
KI-Tools verwenden oft Methoden, um die Anzahl der Tokens zu reduzieren, die an Basismodelle gesendet werden. Zum Beispiel speichern sie automatisch Teile Ihrer Anfrage, die Sie mehrfach verwenden, oder helfen bei der Verwaltung des Kontexts, der in jede Anfrage einbezogen wird.