Tokens y coste
Ahora que ya entendemos en líneas generales cómo funcionan los modelos de IA, exploremos lo que ayudará a comprender cómo piensan estas modelos y cuánto cuesta su uso: los tokens.
Los tokens se pueden considerar como «palabras» que realmente entienden los modelos de IA. Pero hay un matiz: no son exactamente las palabras que nosotros usamos.
Al igual que tu computadora, que en realidad no entiende la letra «A», sino que trabaja con código binario (1 y 0), los modelos de IA también no operan directamente con palabras como «hello» o «world». En su lugar, dividen todo en partes más pequeñas — tokens.
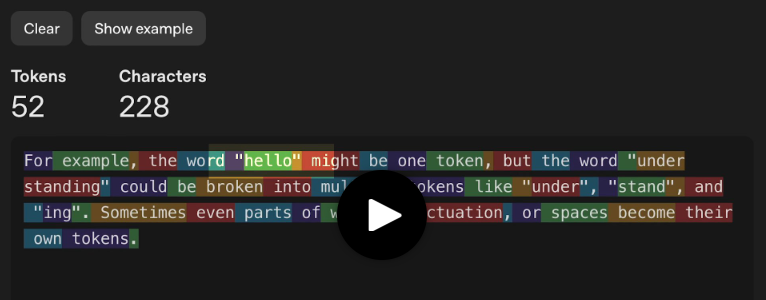
Por ejemplo, la palabra «hello» puede ser un solo token, mientras que «understanding» puede ser varios: «under», «stand» y «ing». A veces, incluso partes de palabras, signos de puntuación o espacios se convierten en tokens individuales.
Ejecuta una consulta y activa la vista del tokenizador
¿Cuáles son algunos consejos para proporcionar mejor contexto al trabajar con asistentes de codificación de IA? Sé conciso.
¿Por qué es importante? Por dos razones:
- El costo se calcula en tokens. Pagas por tokens, no por palabras o caracteres.
- La velocidad de los modelos se mide en tokens. Los modelos más rápidos tienen un mayor TPS — tokens por segundo — devueltos al usuario.
Primero hablaremos del costo, ya que afecta tus gastos al utilizar modelos de IA.
¿Qué son los tokens?
Si continuamos con la analogía del API, los tokens son las unidades con las que medimos y tarifamos el tráfico entrante y saliente.
Los modelos de IA tarifican según dos tipos de tokens:
- Tokens de entrada — todo lo que envías al modelo: tu consulta y el contexto previo de la conversación.
- Tokens de salida — todo lo que el modelo te devuelve como respuesta.
Los tokens de salida suelen costar entre 2 y 4 veces más que los de entrada, porque generar nuevo contenido requiere más recursos computacionales que simplemente procesar lo que envías.
Dado que los modelos de IA tarifican por tokens, comprenderlos es clave para gestionar los costos. Es como saber cuánto cuesta tu servidor.
Es importante elegir conscientemente el volumen de información en el contexto inicial (a esto volveremos más adelante) y cómo dirigir la modelo para que las respuestas sean o concisas o detalladas.
Salida de respuestas en flujo
¿Has notado cómo ChatGPT y otros chatbots de IA parecen «imprimir» respuestas en tiempo real? Esto no es solo un efecto visual — los modelos realmente funcionan así «por debajo de la capa».
Los modelos de IA generan tokens uno por uno, secuencialmente. Predicen el siguiente token, luego usan esa predicción para predecir el siguiente, y así sucesivamente. Por eso ves cómo la respuesta aparece palabra por palabra (más precisamente, token por token).
Las respuestas pueden entregarse en flujo. Esto es conveniente, porque no necesitas esperar a que termine toda la respuesta, lo cual podría llevar minutos, y puedes interrumpir al modelo si empieza a desviarse.
¿Cuál de las siguientes afirmaciones sobre la salida en flujo es verdadera?
La salida en flujo es solo un truco de interfaz; los modelos generan todo el texto de inmediato.
Los modelos generan tokens uno por uno y pueden entregar resultados parciales.
La salida en flujo reduce el costo de los tokens de salida.
La salida en flujo desactiva la posibilidad de interrupción.
CheckReset
Optimización del uso de tokens
Las herramientas de IA a menudo aplican métodos para reducir el número de tokens enviados a los modelos base. Por ejemplo, automáticamente cachean partes de tu consulta que usas repetidamente, o ayudan a gestionar el contexto incluido en cada solicitud.