Tokens et coûts
Maintenant que nous avons une compréhension générale de la façon dont fonctionnent les modèles d’IA, examinons ce qui aidera à comprendre comment ces modèles «pensent» et combien coûte leur utilisation : les tokens.
Les tokens peuvent être considérés comme des «mots» que les modèles d’IA comprennent réellement. Mais il y a un détail : ce ne sont pas exactement les mots que nous utilisons nous-mêmes.
Comme votre ordinateur, qui ne comprend pas la lettre «A» mais travaille en code binaire (1 et 0), les modèles d’IA ne traitent pas directement des mots tels que «hello» ou «world». Au contraire, ils divisent tout en parties plus petites — les tokens.
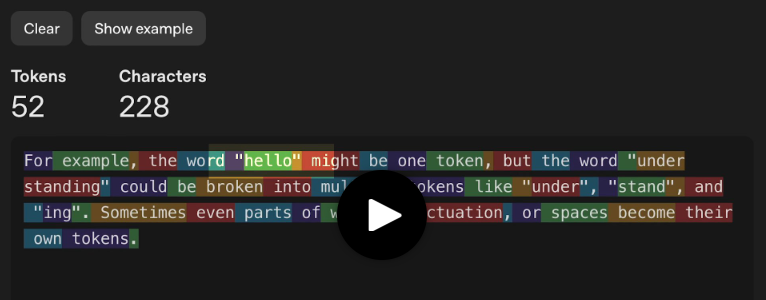
Par exemple, le mot «hello» peut être un seul token, tandis que «understanding» peut en être plusieurs : «under», «stand» et «ing». Parfois, même des parties de mots, des signes de ponctuation ou des espaces deviennent des tokens distincts.
Exécuter une requête et activer la vue du tokenizer
Quels sont quelques conseils pour fournir un meilleur contexte lors de la collaboration avec des assistants de codage basés sur l’IA ? Soyez concis.
Pourquoi cela importe-t-il ? Pour deux raisons :
- Le coût est calculé en tokens. Vous payez en tokens, pas en mots ou en caractères.
- La vitesse des modèles est mesurée en tokens. Les modèles plus rapides ont un TPS (tokens per second, tokens par seconde) plus élevé, ce qui signifie qu’ils retournent plus de contenu à l’utilisateur en moins de temps.
Commençons par parler du coût, car cela affecte vos dépenses lors de l’utilisation des modèles d’IA.
Qu’est-ce qu’un token
Si l’on poursuit l’analogie avec un API, les tokens sont les unités par lesquelles nous mesurons et tarifons le trafic entrant et sortant.
Les modèles d’IA tarifent selon deux types de tokens :
- Tokens d’entrée — tout ce que vous envoyez au modèle : votre requête et le contexte précédent de la conversation.
- Tokens de sortie — tout ce que le modèle vous renvoie en réponse.
Les tokens de sortie coûtent généralement 2 à 4 fois plus cher que les tokens d’entrée, car la génération de contenu nouveau nécessite plus de ressources computationnelles que la simple traitement de ce que vous avez envoyé.
Puisque les modèles d’IA sont tarifés en tokens, leur compréhension est essentielle pour gérer les coûts. C’est comme savoir combien coûte votre serveur.
Il est important de choisir avec prudence la quantité d’information dans le contexte initial (à quoi nous reviendrons plus tard) et de savoir comment diriger le modèle pour obtenir des réponses soit concises, soit détaillées.
Sortie en flux
Vous avez remarqué comment ChatGPT et d’autres assistants d’IA semblent «écrire» leurs réponses en temps réel ? Ce n’est pas un simple effet visuel — les modèles fonctionnent effectivement ainsi «en interne».
Les modèles d’IA génèrent les tokens un par un, de manière séquentielle. Ils prédissent le prochain token, puis utilisent cette prédiction pour prédire le suivant, et ainsi de suite. C’est pourquoi vous voyez apparaître la réponse mot par mot (plus précisément, token par token).
Les réponses peuvent être fournies en flux. C’est pratique, car vous n’avez pas besoin d’attendre la fin de toute la réponse, ce qui peut prendre plusieurs minutes, et vous pouvez interrompre le modèle si celui-ci commence à s’éloigner de votre objectif.
Quelle affirmation sur la sortie en flux est correcte ?
La sortie en flux n’est qu’un effet visuel de l’interface ; les modèles génèrent tout le texte instantanément.
Les modèles génèrent les tokens un par un et peuvent fournir des résultats partiels.
La sortie en flux réduit le coût des tokens de sortie.
La sortie en flux empêche l’interrompabilité.
Vérifier Réinitialiser
Optimisation de l’utilisation des tokens
Les outils d’IA utilisent souvent des méthodes pour réduire le nombre de tokens envoyés aux modèles de base. Par exemple, ils cachent automatiquement certaines parties de votre requête qui sont utilisées plusieurs fois, ou ils aident à gérer le contexte inclus dans chaque requête.