https://cursor.com/it/apprendimento/tokens-e-prezzo
Token e costo
Ora che abbiamo un’idea generale di come funzionano i modelli di intelligenza artificiale, esamineremo ciò che aiuta a comprendere come questi modelli «pensano» e quanto costano il loro utilizzo: i token.
I token possono essere considerati «parole» che i modelli di intelligenza artificiale comprendono realmente. Ma c’è un’eccezione: non sono esattamente quelle parole che usiamo noi.
Come il vostro computer, che non comprende direttamente la lettera «A», ma lavora con il codice binario (1 e 0), i modelli di intelligenza artificiale non operano direttamente con parole come «hello» o «world». Invece, dividono tutto in parti più piccole — i token.
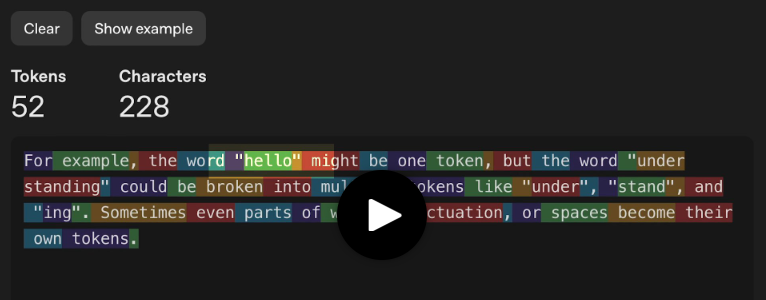
Ad esempio, la parola «hello» può essere un singolo token, mentre «understanding» può essere composto da più token: «under», «stand» e «ing». A volte, anche parti delle parole, segni di punteggiatura o spazi possono essere considerati token separati.
Esegui un prompt e attiva la visualizzazione del tokenizer
Quali sono alcuni consigli per fornire un contesto migliore quando si lavora con assistenti di codifica basati sull’IA? Sii conciso.
Perché è importante? Per due ragioni:
- Il costo viene calcolato in base ai token. Paghi i token, non le parole o i caratteri.
- La velocità dei modelli è misurata in token. I modelli più veloci hanno un TPS (tokens per secondo) più alto, restituiti all’utente.
Parleremo prima del costo, poiché influisce sui vostri costi nell’utilizzo dei modelli di intelligenza artificiale.
Cosa sono i token
Se continuiamo l’analogia con l’API, i token sono le unità con cui misuriamo e tariffiamo il traffico in entrata e in uscita.
I modelli di intelligenza artificiale tariffano in due tipi di token:
- Token di ingresso — tutto ciò che invii al modello: la tua richiesta e il contesto precedente della conversazione.
- Token di uscita — tutto ciò che il modello ti restituisce in risposta.
I token di uscita sono generalmente 2-4 volte più costosi dei token di ingresso, perché la generazione di contenuto nuovo richiede più risorse computazionali rispetto alla semplice elaborazione di ciò che hai inviato.
Poiché i modelli di intelligenza artificiale sono tariffati in base ai token, la loro comprensione è fondamentale per gestire i costi. È come sapere quanto costa il tuo server.
È importante scegliere con attenzione la quantità di informazioni nel contesto originale (a cui torneremo più avanti) e come guidare il modello affinché le risposte siano o concise o dettagliate.
Risposta streaming
Hai notato come ChatGPT e altri chatbot di intelligenza artificiale sembrino «stampare» le risposte in tempo reale? Questo non è un effetto visivo — i modelli operano realmente così «sotto la superficie».
I modelli di intelligenza artificiale generano token uno alla volta, in sequenza. Predicono il prossimo token, poi usano questa previsione per predire il successivo, e così via. Perciò, vedi come la risposta appare parola dopo parola (più precisamente, token dopo token).
Le risposte possono essere inviate in streaming. È comodo perché non devi aspettare il completamento dell’intera risposta, che potrebbe richiedere minuti, e puoi interrompere il modello se inizia a discostarsi.
Quale affermazione sulla risposta streaming è corretta?
La risposta streaming è solo un trucco dell’interfaccia; i modelli generano tutto il testo istantaneamente.
I modelli generano token uno alla volta e possono restituire risultati parziali.
La risposta streaming riduce il costo dei token di uscita.
La risposta streaming disattiva la possibilità di interrompere.
CheckReset
Ottimizzazione dell’utilizzo dei token
Gli strumenti di intelligenza artificiale spesso applicano metodi per ridurre il numero di token inviati ai modelli base. Ad esempio, memorizzano automaticamente parti del tuo prompt che usi più volte, o aiutano a gestire il contesto incluso in ogni richiesta.