- では、悪いコードの書く時間を短くするってどうでしょう?
- はい、そして改行は猫の形にしましょう!
画像には、頭部が炎で燃えている人物がコンピュータの前で鉛筆で描いている様子が描かれており、これは創造的クライシスや燃え尽き症候群を象徴しています。(AIによる画像キャプション)|500x500
現在のインストラクションでは、RAGやセマンティクスのサポートは含まれていません。
IDE
では、このような機能はどうでしょう:コードからその機能を説明する文章を作成する。
PyCharm/IDEAをご利用の場合、LLM(大規模言語モデル)にコードレビューを依頼したり、何でも依頼できる「Devoxx」プラグインが利用可能です。
以下では、このプラグインをLM ServerのAPIサービスと連携させる方法を紹介します。
機能
- ローカルおよびクラウドの言語モデルのサポート:Anthropic、Groq、Ollama、OpenAI、…
- 選択されたコードの断片に対するヒント
- コードレビュー
- コードの機能を説明する文章の生成
インストール手順
- プラグインをインストール(下記参照)
- Ollama、LMStudio、またはGPT4Allが起動していることを確認
- 設定画面でプロンプトを更新
- (任意)クラウドLLMプロバイダーのAPIキーを追加
- プラグインの使用を開始
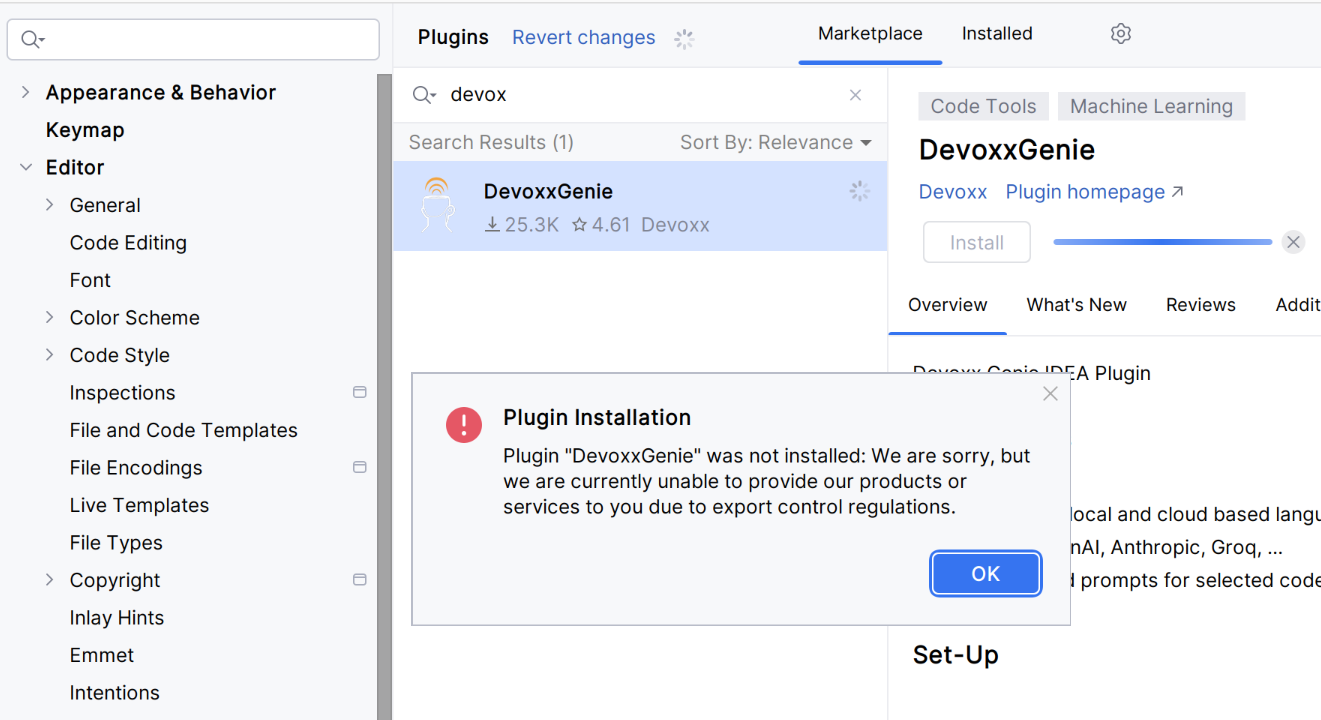
プラグインはマーケットプレイスからインストールしてください。もし、何らかの理由でプラグインがインストールできない場合(輸出管理規制のため、オープンソースならOK):
{kind=link}
…その場合は、他のコンピュータからこのプラグインをコピーするか、GitHubからダウンロードしてください。Ubuntuの例として、以下のフォルダとファイルに注意してください:
# ホームディレクトリ内
$ find . -iname 'devoxx*'
./.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml
./.cache/JetBrains/PyCharmCE2025.1/DevoxxGenie
./.cache/JetBrains/PyCharmCE2025.1/plugins/DevoxxGenie.zip
./.local/share/JetBrains/PyCharmCE2025.1/DevoxxGenie
```- DevoxxGenie.zipファイルを`~/.local/share/JetBrains/PyCharmCE2025.1`フォルダまたはIDEに応じて配置してください。私の場合は、PyCharmCExxxフォルダが存在しないため手動で作成しました。
- `~/.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml`設定ファイルを配置してください。
- オプションです。プラグインとそのアーカイブをキャッシュに追加する必要がある場合があります。
IDEを起動すると、プラグインが事前に設定された状態で表示されるはずです(「インストール済み」タブに表示されます):

## 設定
1. プラグインをインストールした後、プログラムの設定(ファイルメニューから)に移動し、LLMのパラメータ(温度、最大出力トークン数、再試行、タイムアウトなど)を設定してください。必要に応じて、LLMのAPIキーを追加することも可能です。
> DevOpsチームは、HTTPサーバーとして動作するAPIサービスを用意できます。ただし、機密データを扱う場合は、このサービスをリモートで使用しないでください。なぜなら、トラフィックが盗聴され、公開されたデータが悪意ある第三者によって利用される可能性があるからです。
LM Studioで正しくコンテキストウィンドウを定義するには、URL `http://localhost:1234/api/v0`を使用する必要がありますが、これは誤りです。モデルのロード時にコンテキストウィンドウサイズを手動で拡大する必要があります(4096 → 8192)。

「Prompts」タブでは、システムプロンプトとユーザークエリをカスタマイズできます。
システムプロンプトとは、ユーザークエリと同時に送信され、タスクの範囲、検索制約、出力フォーマットを定義するものです。これは非常に重要です。
システムプロンプトから以下の行を削除してください:
The Devoxx Genie is open source and available at GitHub - devoxx/DevoxxGenieIDEAPlugin: DevoxxGenie is a plugin for IntelliJ IDEA that uses local LLM's (Ollama, LMStudio, GPT4All, Jan and Llama.cpp) and Cloud based LLMs to help review, test, explain your project code..
You can follow us on Bluesky @ @devoxxgenie.bsky.social on Bluesky.
すべての言語モデルはMarkdownのフォーマットを理解するため、リスト、サブポイント、コードブロックなど構造化されたプロンプトを作成できます。
> DevOps: デフォルトのプロンプト(制約付きクエリ)は以下ファイルに記述されています。
>
> ```
> ~/.config/JetBrains/PyCharmCE2025.1/options/DevoxxGenieSettingsPlugin.xml
> ```
>
> モデルはロシア語のクエリを英語に翻訳できますが、用語の誤訳や質問の曖昧さは回答品質に大きな影響を与えます。例えば、「ページの説明を検索せよ」と「ページへのリンクを提供せよ」の違いを比較してください。どちらのケースでボットがリンクを提供すると思いますか?期待する結果を明確に要求してください(人間がタスクを提示する際の方法と同様に)。
<br>
2. 「Web search」タブでは、モデルがインターネットと連携するオプション(デフォルトで有効)があります。Google Web Searchの個人APIキーがある場合は使用可能です。
3. RAGの詳細設定は後日追加されます:

## プラグインの使用方法
1. まず、ソースファイルを開き、コードの一部を選択するか、プロジェクトファイルを右クリックしてコンテキストウィンドウに追加します。
「Devoxx」ボタンをクリックしてください:

2. 適切なモデルを選択してください。残念ながら、リスト内の一部のモデルは使用に不向きな場合があります(例:埋め込みモデル)。モデルフィルターは設定できません。

3. コンテキストを定義した後、質問を投げかけたり、事前に定義されたコマンド(/test、/review、/explain、/help)を使用して、LLMに指示を出してください。
4. 選択したLLMから返された回答を受け取ったら、コードの上にあるボタンを使って、コピーしてクリップボードに貼り付けたり、自分のファイルに貼り付けたりしてください。または、スクリプトの動作を説明するためのMarkdown形式のテキスト(英語で表示されるが、プロンプトで使用言語を指定することも可能)を取得できます。
## 出力例:説明
`qwen2.5-coder-14b-instruct`モデルを使用して`/explain`スクリプトを分析した結果:
- コード行数:500行
- モデルのコンテキストウィンドウ:8192(デフォルトの4096から拡張)
- テキストトークン:
```json
"usage": {
"prompt_tokens": 6298,
"completion_tokens": 620,
"total_tokens": 6918
}
-
RTX 5060Tiで分析に要した時間:10秒
-
回答の質:私の場合、十分に満足できる。モデルはコードとコメントから、このコードが何をするかを構造化された説明を作成できました。
スプойラー
もちろん!初心者開発者向けに、このスクリプトの機能をシンプルな言葉で分解して説明します。
概要
このスクリプトは、Tesseractを使用して光学文字認識(OCR)を実行し、PDFおよび画像ファイル(JPG/JPEG)を処理するように設計されています。PDFにテキストが含まれているかを確認し、必要に応じてTIFFおよびPNG形式に変換し、すべての操作を詳細なレポートにログ出力します。
主なコンポーネント
-
色の定義:
GREENおよびNCは、ターミナルでの色付き出力に使用されます。
-
ヘルプ関数(
show_help):- スクリプトの使用方法、説明、オプション、および実行方法の例を提供します。
-
引数解析:
- スクリプトは
whileループとcase文を使用してコマンドライン引数を解析します。 - オプションには、DPI設定、圧縮タイプ、OCR言語、処理後のTIFF/PNG/TXTファイルの保持有無などが含まれます。
- スクリプトは
-
検証:
- 提供されたDPIが有効範囲(72〜1200)内であるかを確認します。
- 圧縮アルゴリズムがサポートされているタイプ(
group4、lzw、zip)であるかを確認します。
-
ログ設定:
- すべての操作と出力を記録するログファイルを初期化します。
-
ファイル検出:
- 指定されたディレクトリ内のPDFおよびJPG/JPEGファイルを
findコマンドで検出します。ディレクトリが指定されていない場合は、現在のディレクトリを使用します。
- 指定されたディレクトリ内のPDFおよびJPG/JPEGファイルを
-
PDFファイルの処理:
- 各PDFに対して、
pdftotextを使用してテキストが既に含まれているかを確認します。 - テキストが見つかった場合は、テキストを含むPDFとしてログ出力します。
- テキストが見つからない場合は、PDFをTIFFおよびPNG形式に変換し、TIFFに対してOCRを実行します。
- 各PDFに対して、
-
画像ファイルの処理:
- 各JPG/JPEGファイルに対して、Tesseractを使用して直接OCRを実行します。
-
統計計算:
- 認識された文字数の合計、1ファイルあたりの最大文字数、文字数の分布、その他さまざまな統計を計算します。
- スキャンされたPDFの割合および平均認識速度を計算します。
-
要約生成:
- 処理されたファイル、統計情報、使用されたオプションを含む詳細な要約レポートを生成します。
- この要約をターミナルおよびログファイルの両方に記録します。
使用例
特定のオプションでスクリプトを実行する場合:
./work2.sh --dpi 600 --compress lzw --lang rus+eng --no-keep-tiff --no-keep-txt ./docs
```このコマンドはDPIを600に設定し、TIFFファイルにはLZW圧縮を使用し、OCRにはロシア語と英語を指定し、処理後にTIFF/PNG/TXTファイルを保持しないようにします。
### 結論
このスクリプトは、OCR機能を備えたPDFおよび画像のバッチ処理に適した包括的なツールです。詳細なログと統計情報が提供されるため、文書処理タスクにおける自動化と分析に役立ちます。
結論
非常に便利なツールで、最適な解決策の探索(たとえば、関数やドキュメントの作成、可視化・ログ記録など)やドキュメント作成に活用できます。
仕組み
開発中の完全な仕組みは以下の通りです。次回の記事では、GitLabでのAI Code Reviewをマージリクエスト(MR)前に活用する方法について解説します。
graph LR
classDef pclass fill:#f5f5dc
classDef wclass fill:#f96
classDef pmclass fill:#4f7
classDef yclass fill:#ff9
classDef oclass fill:#ffbf00
B(IDEA) -- |Code pre-Review| --> B1(AI Devoxx):::pclass
B1 -- --> C(修正):::wclass
C -- --> D{自己チェック}:::oclass
B -- |あなたのコードは完璧| --> F
F -- --> H2{Code Review}:::oclass
H2 -.-> |改善が必要| B1
D -- |確認済み| --> F(MR):::pmclass
H2 -- --> E(Merged)