でも、今ではこの箱で火事は消せない
専門的変形:仕事によって生まれる悪い習慣
すでに書いたが、IT業界では、1日何百回もの切り替えが日常であるため、家庭での習慣が仕事のスタイルを決めるのではなく、逆に仕事が私たちに「問題を即座に解決する」習慣を身につけさせている。その解決は、十分な事前分析が欠けていることが多い。
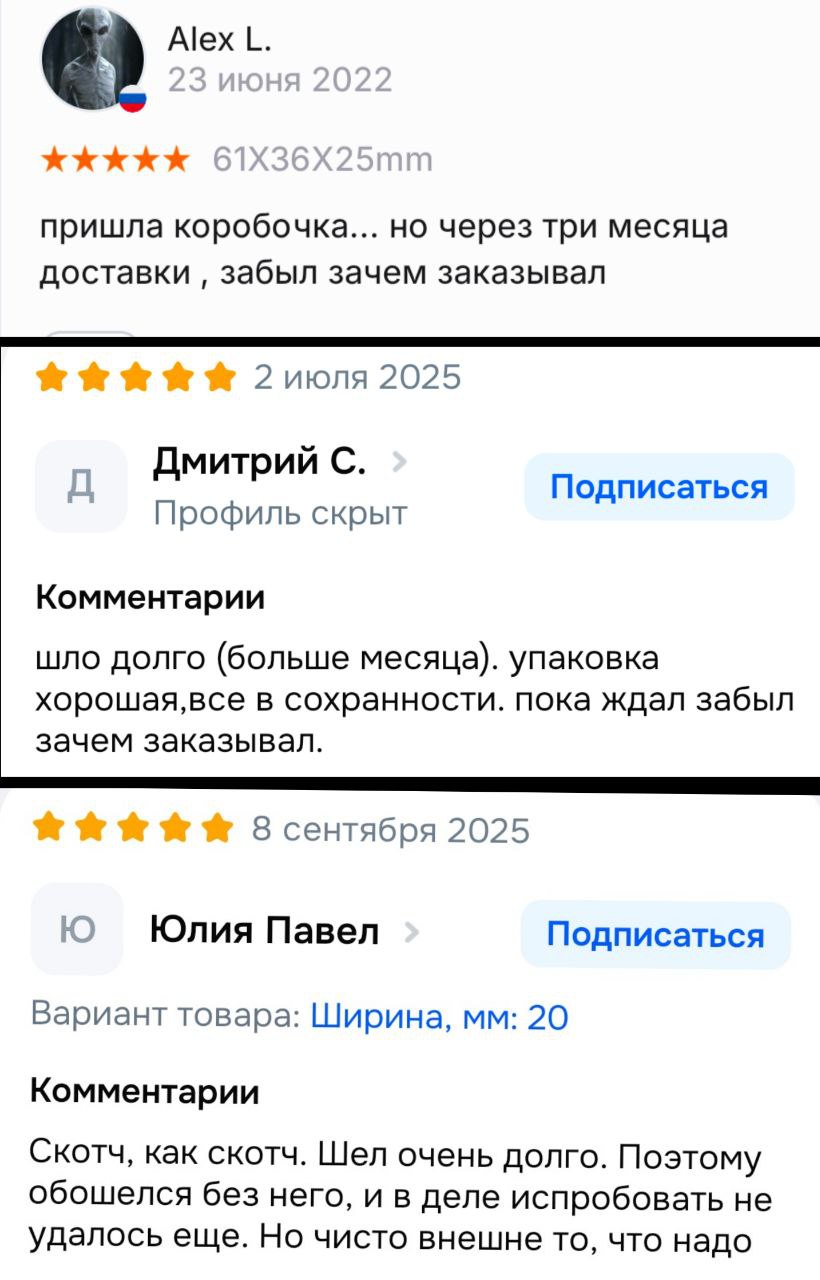
即時的な結果への誘惑に陥る人々の例をいくつか紹介します。悲しいことに、注文の瞬間には「ワンクリックで購入する」ことが問題解決の唯一のステップだと考えていた人たちがいたのです。
では、誰がこれを作ったの?想像してみてください。大企業のCTOやPMが同じように行動します。彼らはDevOpsチームに「即日対応の解決策」を依頼します。期待された「最新技術の箱」(Apache Kafka、オブジェクトストレージS3、シャード化されたデータベース、セマンティック検索など)を受け取った後、彼らは不快な真実に気づきません:この製品にはインストール・設定・運用の説明書が付属していません。デプロイスクリプトやスケーラビリティ、パフォーマンスモニタリングの機能もありません。最も重要なのは、DevOpsチームにこれらの技術が実際に導入されるという事実を事前に通知していなかったことです。
注文から3か月が経過しましたが、期待された軽減の代わりに、リーダーは新たな問題のサイクルに直面します。その失望は次のように表現できます:「箱が届いた…でも3か月の配送期間が過ぎて、なぜその箱を頼んだのかを忘れてしまった」。速やかな勝利への願望は運用の混乱に変わり、戦略的計画の欠如は技術を無限の困難の源に変えます。## 次のリリースに向けてKafkaが必要です
誰かのテクニカルリーダーが「ハブリ」の記事「リアルタイムイベントのストリーミング」を読んで、頷き、「我々にはKafkaが必要だ」と言い切った。提案の依頼もなく、アーキテクチャのレビューもなく、DevOpsの参加もなく。似たような経験をしたことはありませんか?
はい、Kafkaはオープンソースです。はい、スケーラビリティがあります。しかし、Kafkaをクラスターで運用しているどのチームにも聞いてみてください:Kafkaの成熟度は非線形であり、階段状の関数です。
- 0〜6ヶ月:「すべて正常に動作しています!」 - 分区の隠れた不均衡、ブローカーへの非均一な負荷、制御不能な遅延
- 6〜12ヶ月:「なぜ遅延が増えるのか?」 - 手動の再配分、火事の消火、分散された責任
- 12ヶ月以上:「誰がこれに責任を持つか? どうやってこのシステムをオフにできるのか?」 - 「ゾンビの生成」、外部サポートの無視されたコスト
DevOps向けの自動化、監視、ライフサイクル管理がなければ、Kafkaはデータストリームではなく、Telegramへのアラートの連続体を提供します。## S3互換ストレージ?素晴らしい。それではそれを保護しましょう
Ozonチームは、LuscaをS3互換ストレージに移行するのに数ヶ月を費やしました — それはS3が難しいからではなく、イベント駆動型の上に強い一貫性を実装し、データベースのバックグラウンドプロセスを管理し、テラバイト単位のデータを復旧するという課題が、深い専門知識と時間を要するからです。
さらに悪いことに、DevSecOpsの衛生管理(イメージスキャン、シークレットの保管、L7ネットワークポリシーなど)を行わずにコンテナで展開すると、ストレージを作成するどころか、脆弱性のベクターと技術的\u003cdel\u003e負債\u003c/del\u003eを生み出します。火事。
データベースのシャーディング:回復不能な点
垂直スケーリング、クエリの最適化、キャッシュレベル、読み取り用レプリカをすべて試した後でシャーディングを行うべきです。これは最終手段です。
シャーディングを間違った方法で行うと、「熱いシャード」、レプリケーション遅延、シャード間でのクエリ障害が発生します。特にシャーディングキーが不適切に選ばれた場合、その影響は顕著です。 DevOps用のバックアップ、モニタリング、リバランシングツールを使わずにシャーディングを実施すると、スケーラビリティを可用性に代えることになります。
重要なのは、このシャーディングを「戻れない」こと。一度導入したシャーディング構成は、再び元の状態に戻すには、数倍の苦労が必要になります。
そして、本質的な問題は技術的ではなく組織的です
どのベンチマークも、現代のDevOpsにおける最も狭い部分が「知的リソース」「メモリ」「処理速度」ではないことを示してくれません。なぜなら、それは「ロードマップの問題」から生じる意思決定の遅延だからです。一部の企業ではDevOpsのRoadmapが存在しません。また、ある企業ではそもそも存在しないのです。なぜなら、戦略は膝の上でのデモ販売に委ねられているからです。
反応型実行の文化は、どのような結果を招くのでしょうか?
- CTOが開発の注文を署名した後、エンジニアは仕様書ではなく「この機能を100台のサーバーで自動化してください」という指示を受けます。ドキュメントなし、明確なアーキテクチャなし、テストカバレッジなし。
- 3か月後には「なぜこんなに遅いのか? そもそもなぜこれを構築したのか?」という声が聞こえます。
これはリーダーシップではありません。これは責任回避です。
反応型組織におけるDevOpsチームは、良い意図を燃やし、ログやグラフの幽霊に追いかけて、自分が設計しなかったものを修正し、自分が所有しなかったものを守るのです。何かが壊れたとき、責任は人にあるのではなく、プロセスにある。これはDevOpsではなく、「YasnoOps」(明確な視点を持つチーム)です。成熟したDevOps文化は「誰がミスをしたか」を問いません。むしろ「何が故障を引き起こしたか」を特定し、システムそのものを修正するのです。あなたのケースでは、システムは「ロードマップの欠如」と「意思決定段階でのDevOpsの関与の欠如」に他なりません。
ロシアの文脈:スピード対安定性
2023~2024年、ロシアのSaaS市場は数兆ルーブルにまで成長しましたが、これは安定的で予測可能な市場ではなく、スピードを競う「スロー・コッキーナ」です。現代性をアピールする競争は、現代性を支える土台を壊してしまいます。我々は、ГосТех が示す方向性に向かって進むべきです。統一されたログ記録、認証されたAPI、モニタリング、FSBの要件に準拠した設計、および供給チェーンの整合性。しかし、急いで構築されたインフラや、即時対応型の意思決定に基づくアーキテクチャに、どのように標準を統合するのか?DevOpsチームが設計段階に巻き込まれていない場合、どのようにセキュリティを確保するのか?
このような企業は、インフラを「第二の優先事項」とみなしています。 これはエンジニアリングの失敗ではなく、期待管理の失敗です。
状況を変えるには?
解決策は、立場の変更です:
- 「今すぐ構築して販売する」→「この技術を近い将来、自社が持続的に管理できるか?」
- 機能の導入速度 → プラットフォームの持続可能性
- DevOpsを「救急チーム」→ DevOpsを「共同アーキテクト」とする
(注:「ГосТех」はロシア語の「ГОСТЕХ」(国家技術基準)を指し、日本語では「ГОСТ」や「ГОСТех」のまま使用するか、必要に応じて「国家技術基準」などと訳すのが適切ですが、ここでは原文のまま維持します。)大企業はこの道を歩んできました。彼らは自社の roadmap を公開しています。彼らは安定性のためにリリースのスケジュールを延期します。彼らはリリース日だけでなく、運用準備度を測ります。
彼らは単純な真実を理解しています - コントロールのないスピードは柔軟性ではなく、漂流です。これは特に政府機密が関わる企業向けソフトウェアにおいては許されません。
クリティカルな状況からの脱出には転換が必要です
- 反応型管理から予防型計画へ - DevOps の roadmap を開発し、早期段階で関係者全員を巻き込む。
- 実行者から戦略的パートナーへ - DevOps を製品開発の不可欠な要素として認めること。
- 無秩序な導入から計画的な変革へ - パイロット導入とイテレーションによるギャップの発見を重視した段階的導入。
- そして、最後に「購入」ボタンが自動で押されることがなくなるでしょう
 現代の現実、特にゴス・テクの状況下では、運用成熟度を無視することは、単なるリスクではなく戦略的なミスです。
現代の現実、特にゴス・テクの状況下では、運用成熟度を無視することは、単なるリスクではなく戦略的なミスです。